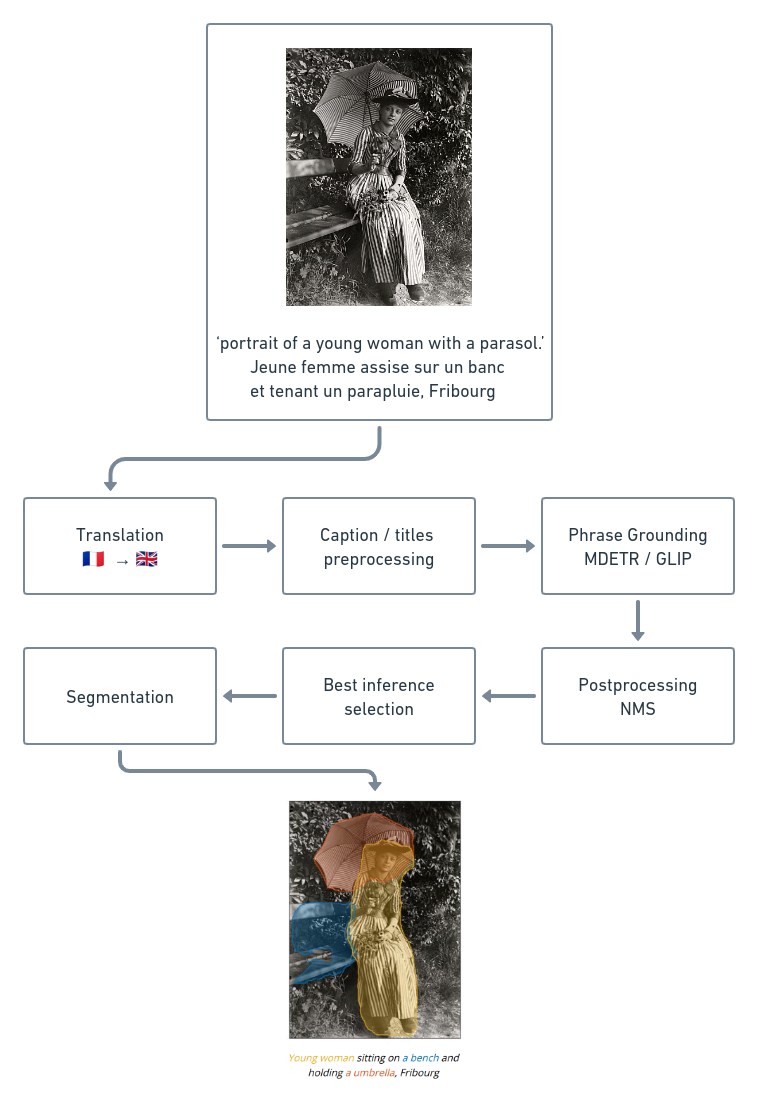
Many institutions, such as libraries and museums, have begun to digitize their collections in order to make them more accessible to a wider audience. However, the use of these digitized images has typically been limited to remote access and research tools. This projects aims to explore the potential for the valorization of these digitized heritages by augmenting the images with the use of state-of-the-art computer vision and natural language processing techniques.
The pipeline consists of six steps. It takes as input an image with its title in French and an AI-generated alternative caption in English.
Since the phrase grounding models selected were trained on English captions, the titles of the images need to be translated from French to English. A pretrained machine learning model, MarianMT, which is a multilingual machine translation model trained on the on the OPUS corpus, is used for this purpose.
The captions and titles are preprocessed in preparation for phrase ground-
ing. This is achieved by converting the text to lowercase and removing the
following expressions: ”portrait of”, ”photograph of” and ”black and white
photo of”.
As this dataset consists of images from Fribourg, there are many mentions
of Fribourg in the title, which can potentially confuse the phrase grounding
models. Therefore, the following mentions were removed: ”canton de fri-
bourg”, ”of fribourg”, ”(fribourg)”, ”[fribourg]” and ”fribourg”.
The expressions ”group of” and ”a group of” have also been removed, as
the phrase grounding algorithms would often give the label ”group” rather
than the subject of the group. For example, with the expression ”a group of
musicians”, the phrase grounding algorithm would choose the label ”group”
rather than ”musicians”.
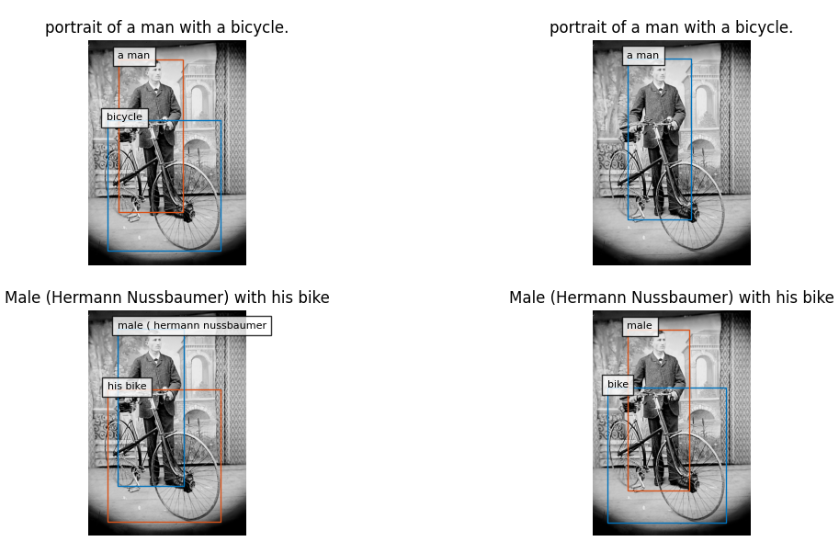
Phrase grounding involves detecting the objects in an image that are mentioned in a caption. In this project, two state-of-the-art models were used for this task: GLIP (GLIP-L - 430M parameters) and MDETR (EfficientNet-B5 - 169M parameters). Inference was run on both the caption and the title for each image.
Both MDETR and GLIP tend to create several bounding boxes for an object. To address this, non-maximum suppression (NMS) is applied, a technique that removes bounding boxes that overlap too much with other bounding boxes. The standard NMS algorithm is used twice: once label-wise with a threshold of 0.5, and once global with a threshold of 0.9.
Each image has four phrase grounding results: two from the caption and two from the title, as it has been run on GLIP and MDETR. The best phrase grounding results are selected using a user-friendly GUI.
The most selected combination is GLIP on the caption.
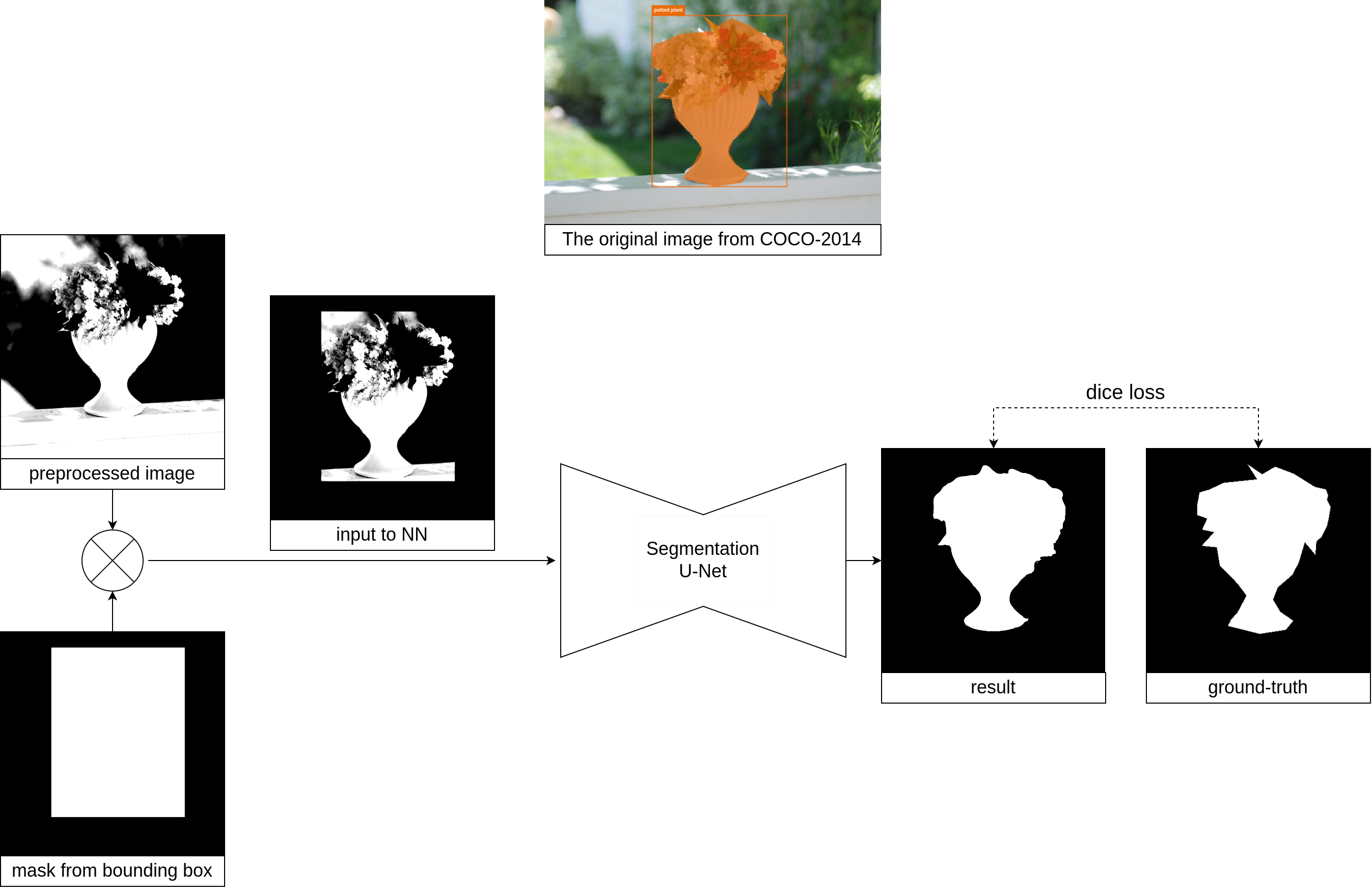
In order to further augment the images, the detected objects are segmented in the images. The bounding boxes from the phrase grounding results are used to crop the objects and then segment them. Initially, GrabCut was chosen for this task due to its simplicity, but its performance was disappointing, especially on black and white images, which make up the majority of the dataset. GrabCut is based on color information to distinguish between foreground and background pixels. In a black and white image, there is only one color channel, so there is less information available for GrabCut to use in making segmentation decisions. This led to designing a custom class-agnostic segmentation model on PyTorch.
where $A$ is the predicted bounding box or segmentation mask and $B$ is the ground truth. The IoU score ranges from 0 to 1, with higher values indicating better performance. A mean IoU of 0.77 indicates that the model is performing well but there is still room for improvement.
The model also achieves mean pixelwise precision and recall scores of 0.82 and 0.91, respectively. Pixelwise precision and recall are other common evaluation metrics used in object segmentation, and they measure the fraction of true positive pixels out of all predicted positive pixels (precision), and the fraction of true positive pixels out of all actual positive pixels (recall). These values provide additional insight into the performance of the model and can be used to identify any potential trade-offs between precision and recall. A higher recall than precision seems to indicate that the model is more sensitive to detecting positive pixels but may be less accurate in predicting them. In other words, the model is more likely to identify most of the positive pixels (high recall), but some of the predicted positive pixels may be incorrect (lower precision).
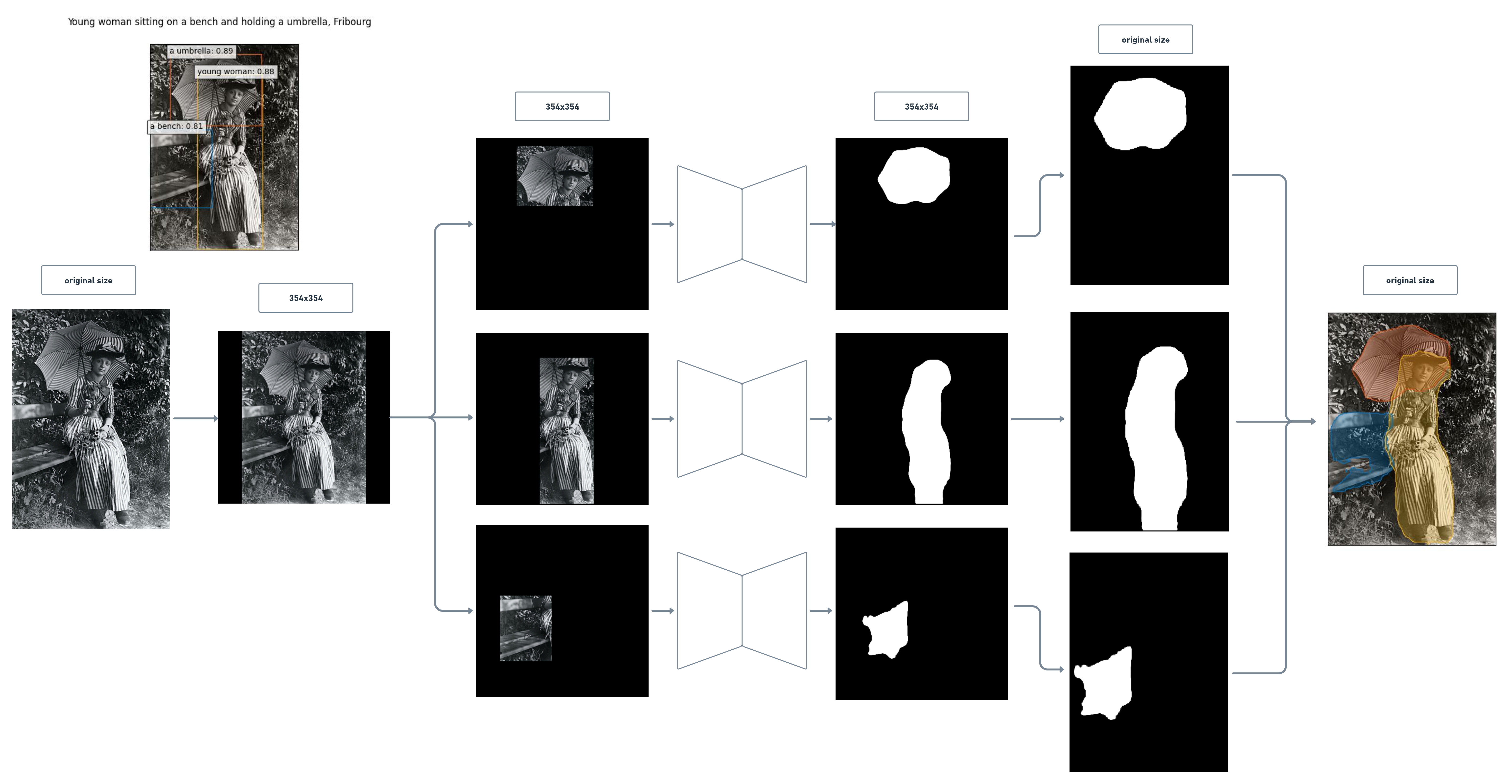
The model was run on the images to segment the detected objects using the bounding boxes from the phrase grounding results. The preprocessing for this step was slightly different from the fine-tuning process: the image was resized to 352x352 with padding, normalized, and then turned into a tensor. After the inference, the segmentation was multiplied by the mask to remove any noise and was resized to the original size of the image.
A comparison between GrabCut and the deep learning model is shown in in the figure below, on color and black & white images, for one and five inferences. On average, GrabCut takes 259ms per inference, whereas the deep neural net model only needs 47.3ms , which makes it not only better but also faster.
The segmentation model performs better on single objects than on groups of objects, as shown in the example below, where the “children” and “students” are better segmented on the right image than on the left.
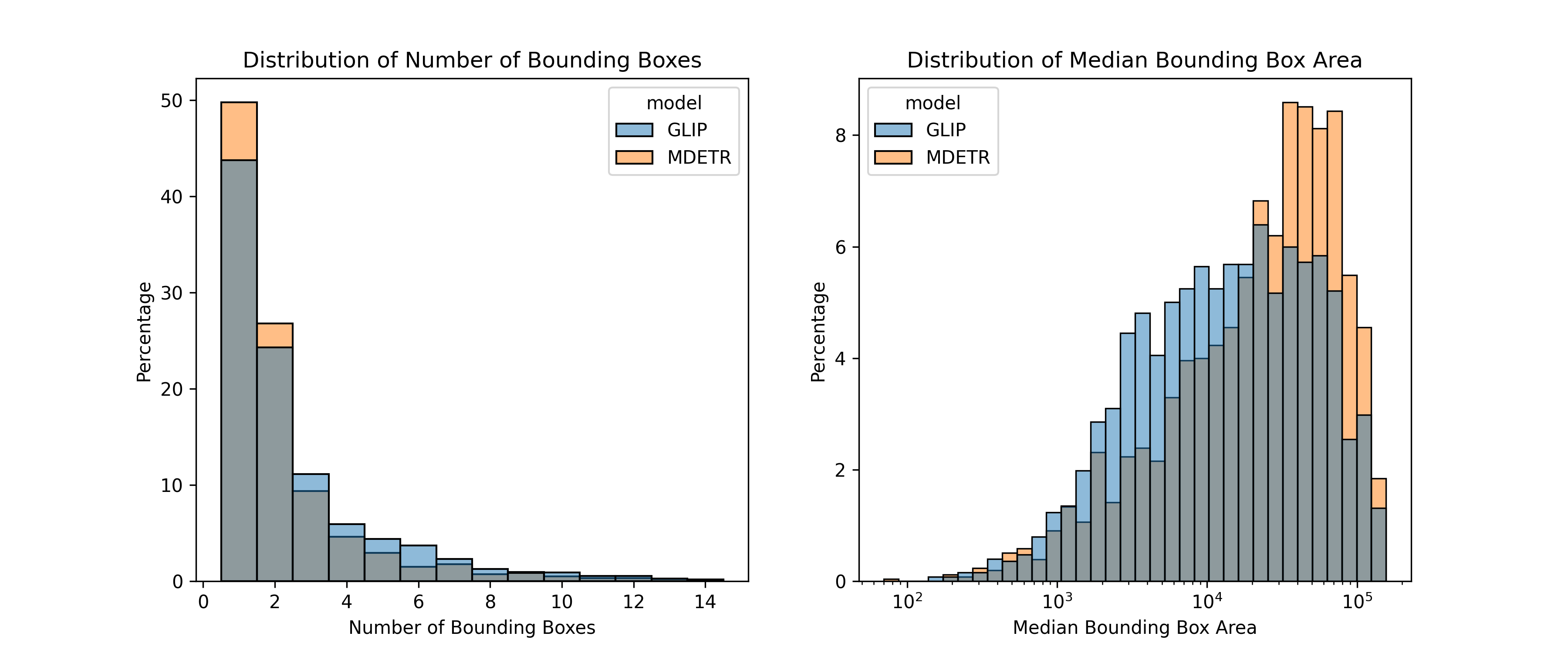
The number of bounding boxes and their median area were compared between GLIP and MDETR to see which model performs better on phrase grounding.
This shows that GLIP tends to output more bounding boxes than MDETR, and they also tend to be smaller. This suggests that GLIP is a more suitable option, as its bounding boxes would likely lead to better segmentation than MDETR.
Manually selecting the best inference for each image in a dataset can be time-consuming, especially when dealing with large datasets. To address this issue, several different methods for automatic classification of the best inference were tried.
Both a random forest classifier and a MLP classifier were unable to perform better than always selecting the most popular combination. They were trained using the statistics collected during manual selection as features, such as the number of words in the caption and title, as well as the number of bounding boxes and their minimum, maximum, and median area for each combination of [caption, title] and [GLIP, MDETR].

crowds gather to watch the parade.

painting artist in his studio.

portrait of a man sitting on a bench.

Male (Hermann Nussbaumer) with his bike

women standing in front of a church.

photograph of a group of women sitting on a bench.

photograph of a family with children.

Music Society

steam locomotive pulling a passenger train.

photograph of a group of men and women seated around a table.

a group of men working on a swing set.

photograph of a house with a horse and carriage.

Stone bridge with diligence, Wünnewil-Flamatt

Castle of Ueberstorf (Ratzé), Sancta Maria Institute (boarding for girls)

portrait of a man with a beard.

Portrait of the wife of Mr Baeriswyl in the company of another young woman, Fribourg

Portrait of a young couple on their wedding day, [Fribourg]

Miss Ida Maurer in her uniform at the boarding school in Orsonnens, [Fribourg]

politician as a young woman.

portrait of a girl and a boy.

monarch and noble person pose for a family portrait.

tourists on a boat at night.

photograph of politician and his family.

portrait of a girl and a boy.

Jean Ramstein, son, in military uniform during the occupation of the borders during the First World War [Fribourg]

Forgerons en car in front of the store, employees of Mr. N. Cotting successor of Théobald Berguin, [Rue de Morat 246 (Act. No. 47), Fribourg]

portrait of a young man standing in front of a house.

Shop "A la Ville de Paris", Rue de Lausanne, Fribourg

Shop "Modes Chapellerie J.M. Meier", Rue de Romont, Fribourg

the wedding of person and noble person.

Portrait of a child, Fribourg

photograph of a group of men standing in front of a flag.

politician with his wife and their children.

photograph of a group of boys standing on top of a mountain.

Boat trip on Lake Morat

Picnic between women during military manoeuvres, Granges-Paccot

photograph of the swimming pool.

photograph of a group of people in front of a building.

a medical team working in a hospital.

actor in a scene from the film.

Fountain of the Force, rue de la Neuveville, Fribourg

Fontaine Sainte-Anne, Place du Petit-Saint-Jean, Fribourg

a man with a beard.

a man carrying a load of hay on his head.

statue of person in the church.

the wedding of noble person and businessperson.

Chartreuse de La Valsainte, cell of a monk, Cerniat

Fribourg from the Grand-Places

portrait of a young boy.

monarch and noble person in the cloisters.

portrait of a little girl.

tourist attraction in the past, history.

Houses in the town of Kippel, Lötschental (Valais)

children playing in the street.

Fisherman repairing his net

Capuchin Brother in the Church of the Count of the Capuchins, Fribourg

Gruyères, its castle and Moléson from the east

close - up of a woman's hands embroidering clothes.

portrait of a young girl.

person in the kitchen of her home.

Sisters of Providence caring for a child, Fribourg

a man playing with pigeons.

Sister of Providence reading to children, Fribourg

a fisherman.

ruins of an old castle.

Fileuse and its wheel, [Fribourg]

a statue of builder in a church.

a group of children playing in the courtyard of a house.

a roof.

a man works on the roof of his house.

Joseph Bourqui, "Biscuit" (1891-1959), Fribourg

a cowboy on his horse in the mountains.
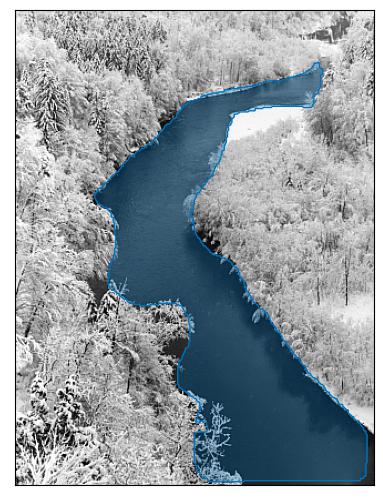
Sarine, the river in winter near Fribourg

composer playing the organ at the organ.

religious leader blesses a child during his visit.

religious leader blesses a child during his visit.

Promenade de Monsieur le Curé, Lötschental

children playing in the mud.

Peasant repairing his fake, [Fribourg]

children planting a tree in the garden.

a flock of sheep in the mountains.

a young girl feeding chickens on a farm.

a young girl and a boy sitting on a bench in a garden.

a priest blesses a child during a mass.

photograph of a family in their living room.

a cow and her calf in a field.

monarch and noble person celebrate the wedding of noble person and businessperson.

a farmer ploughs his field with a horse and cart.

painting artist, portrait of the artist.

religious leader blesses the altar during a mass.

Door and corridor (with crucifix) of the Visitation convent, Fribourg

photograph of soldiers sitting at a table.

Little boy drinking milk in the mountains, [Fribourg]

Children on their way to school (countrypath)

Singaporean campaign

a farmer ploughs a field with his oxen.

Child (little girl) sewing in front of an old decorated wardrobe, Wünnewil-Flamatt

soldiers on a mountain ridge.

a young boy in a straw hat sits on a wooden cart pulled by a tractor.

Hatlet in a Fribourgeois peasant family

soldiers working in the field.

black and white photo of a truck driving along a dirt road.

photograph of politician at his desk in his home office.

Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey on the road to the Alps, Fribourg

Students in theology and religious at the University of Fribourg

Child with a ball, Fribourg

Foreign students visiting the University of Fribourg, site de Miséricorde

a man riding a bicycle in the woods.

children playing in the street.

children playing in the street.

a a man looking out over a city.

the skeleton of a dead man.

The city of Fribourg seen from the sky

Monsignor Paul von der Weid during the Fête-Dieu, Place Notre-Dame, Fribourg

mountain range in the 1950s.

Roof picker, [Fribourg]

Barques in a harbour, [Rhin]

dandelion seeds blowing in the wind.

suspension bridge over the river.

flowers on a window sill.

street in the old town at night.

a group of men stand in front of a snow - covered car.

Men (silhouette) on the stairs of the Court-Chemin, Fribourg

a photograph of a woman dancing in front of fireworks.

automobile model on the road.

a student working on a computer in the library.

Portrait of Georges Python, University of Fribourg

Ferpicloz, Sarine, Reformed German School, opened in 1862, closed in 1970

Granges-Paccot

Hotel de la Croix-Blanche, Treyvaux

Châtillon, from the south, Broye

Pensionat du Sacré-Coeur, Estavayer-le-Lac (Switzerland), dormitory and toilet

Households, general view

Montagny-la-Ville

Montagny (canton of Fribourg, Switzerland), church and tower

Montet (Fribourg), church and main street

the church in the village.

the statue of person in front of the church.

aircraft model in the field.

Château de Surpierre

photograph of a farm in the 1930s.

photograph of a farm in the 1930s.

Mézières (Fribourg), school and dairy

Torny-le-Little, the church

photograph of a group of women working in a classroom.

Romont, the castle

Romont, the casino

Torny-le-Grand

person and his wife, in front of their home.

Gurmels

photograph of a house in the neighborhood.

photograph of a village in the mountains.

Bull and the Gruyerian Alps

Dam of the Jogne and water intake at Châtel-sur-Montsalvens, [near Charmey]

Château de Corbières

Echarlens (Gruyère), general view and Gremaud bakery

Entrance to the Château de Gruyères

Psychiatric institution of Marsens/Gruyère, aerial view

Pont-la-Ville

Riaz - District Hospital

The Rock

photograph of a woman looking at books in a library.

photograph of a nun in the kitchen.

a man with his dog on a street.

Pensionnat St-Joseph, Gouglera near Eichholz (Ct. Fribourg), [comune Giffers]

church in the village of person.

Hotel Pension Alpenklub, Planfayon, [Plaffeien] (Ct. Fribourg)

Fliegeraufnahme von Schmitten/Frbg

Ueberstorf

Fribourg, Champ des Targets, Café des Chemins de fer, Ls. Cottage, prop. Tel. 1050, [Perolles]

Pensionnat de la Providence, Fribourg, Study room, [Neuveville]

Fribourg, baths and sports park of La Mottaz, [Neuveville]

photograph of a young girl standing in front of a building.

Fribourg, baths, [Neuveville]

painting artist on the banks.

The great cantonal pilgrimage of 24 September 1933 to the miraculous Virgin of Bourguillon

soldiers of the march through the streets.

tourist attraction in the 1920s.

troops march through the streets.

a group of soldiers stand in front of a building.

[Fête-Dieu 1914 - Fribourgeois regiment in the courtyard of the Cordeliers at the Mass said by Monsignor Hubert Savoy]

soldiers in front of a cannon.

crowds gather in front of the building.

soldiers on horseback in front of the building.

photograph of a group of men sitting in a car.

General Pau en Gruyère (12 June 1917)

photograph of a group of people standing in front of a building.

horse and cart in front of a house.

transit vehicle type in the 1930s.

photograph of a group of boys and girls standing in front of a school bus.

photograph of a group of people standing in front of an airplane.

Remains of the aircraft piloted by Léon Progin, following a fatal accident in Menziswil

aircraft model was the first aircraft to enter service.

photograph of a group of soldiers.

Official map of the Second General Congress of Swiss Catholics : IIer Schweizerischer Katholikentag : Fribourg, 22-25 September 1906

religious leadership title in the crowd.

photograph of military commander inspecting troops.

crowds gather to watch the procession.

monarch and noble person at the wedding of person and noble person.

monarch and noble person at the wedding of person and noble person.

photograph of a horse - drawn carriage.

Fribourg - University

photograph of a group of men with a horse and cart.

photograph of a family in front of a house.

photograph of a farmer with his cow.

a boy with a horse and cart.

painting artist, landscape with a family.

men with a horse and cart.

photograph of a group of men drinking beer in a restaurant.

father and son in the countryside.

pilgrims gather for a mass.

crowds of people on a horse - drawn carriage.

children in a car decorated for western christian holiday.

women in traditional dress marching in a parade.

troops marching through the streets.

photograph of a group of young people.

railway station in the 19th century.

horse - drawn carriages in the streets.

Bulle, the workers' houses (new quarter)

photograph of the entrance to the chapel.

photograph of a group of women standing in front of a building.

photograph of a man standing on the roof of a building.

Billens and Romont Hospital

ski area showing snow as well as a small group of people.

swimming pool in the mountains.

painting artist, illustration for the story.

photograph of a man riding a horse.

crowds gather at the start of the race.

Bulle Castle

rail transport business in the 1930s.

Modern hotel in Bulle

St Denis Fair in Bulle

St-Denis Fair in Bulle

Bulle, St-Denis Fair

a large tree on the side of the road.

Bulle, the pool

Bulle and its castle, in winter

Bulle pool in Gruyère

photograph of a house in the mountains.

Chénens. Chapel and school houses

The Museum of Country and Val de Charmey: Fountain Louis Angéloz

water reservoir lake in the mountains.

construction of the bridge over river.

[Charmey]: Bridge of Javroz

a bus in front of a building.

a man with a horse and cart.

Skiers on the slopes of Moléson with views of the Dent de Broc and the Dent de Follerian

photograph of a herd of cows grazing in a field.

mountain range in the distance.

Cars parked at Place des Ormeaux, Fribourg

Feasted family poses in front of the house

photograph of a family in front of their car.

religious leadership title in a nun's room.

photograph of a family in a field with a tractor and a pick - up truck.

actor as person in the film.

photograph of a woman working in a sewing machine.

soldier with a machine gun in the forest.

photograph of a woman working in a factory.

a nun with her children.

religious leader celebrates western christian holiday.

a statue of film character.

Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey, Fribourg

a family poses for a photo in front of a christmas tree.

film character on a donkey.

religious leader leads a procession through the streets.

Child (little girl) standing in a chair, [Fribourg]

photograph of women in the cloisters.

Young woman sitting on a bench and holding a umbrella, Fribourg

Electric plant, Charmey

photograph of a group of women.

photograph of a group of people.

photograph of a group of women seated around a table.

photograph of a group of people seated around a table.

photograph of a group of men and women.

photograph of a group of men.

photograph of the cricket team.

portrait of a young woman.

photograph of workers in a factory.

Steam boat "Yverdon" arriving at dock on Lake Morat

Skating on Lake Morat (Seegfröni)

women working in a sewing machine.

person, left, and person, right, stand next to automobile model.

a man stands on the shore of a lake with a fishing boat in the background.

Exercise of the body of firefighters at the house Spirgi, rue Principale (Hauptgasse), Morat

a horse - drawn carriage passes through the streets.

a horse - drawn cart in the streets.

portrait of a man with glasses.

a man stands on the shore of a lake.

a group of people standing in front of a restaurant.

students working in a classroom.

elephants walk down a street.

crowds gather to watch the opening ceremony.

photograph of a family sitting in a car.

ballet dancers in the 1960s.

Woman in a boat on Lake Morat

person working on a machine.

photograph of politician addressing a crowd.
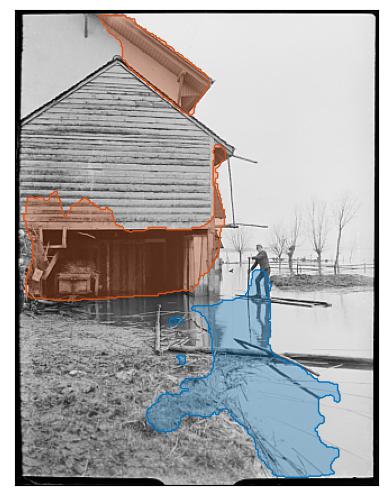
House and flooded land, Lake Morat, flood

Two women (Emma Wildanger-Haas and her mother) playing chess

Living room with large window (chairs, table, sofa)

boys playing football on a soccer field.

Woman (Emma Wildanger-Haas) walking her dog by Lake Morat

Französische Kirchgasse (street of the French Church), Morat

photograph of a woman standing in a doorway.

portrait of a woman standing on a dock.

physicist and person at work in the laboratory.

a woman walks through the rubble of her home.

Solemnity, young girls dressed in white wearing garlands, behind school, Morat

Solemnity, young girls dressed in white wearing garlands, behind school, Morat
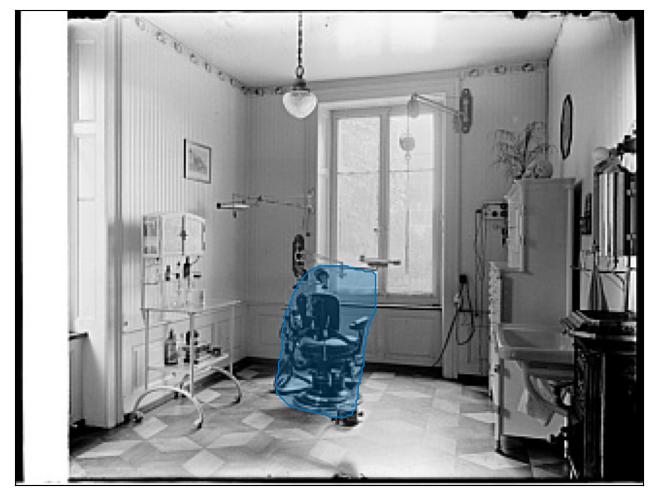
photograph of a patient in a hospital room.

photograph of a bride and groom standing in a field.
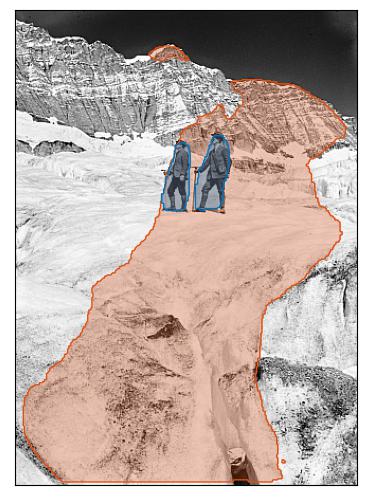
hikers walking on a snow covered mountain.

Delivery of flour bags by Bossy mill in Serrières, rue de l'Hôtel de Ville, Morat

a flooded road.

Lake of Morat frozen, says "Seegfrörni"

Terrace of the restaurant of the Crown Hotel, Morat

a group of people standing in a field.

Baths and beach of Morat

soldiers of the march through the streets.

fishing boat on the beach.

children playing in a field.

Couple (male and female) in grass, Morat

soldiers digging a trench in the streets.

troops marching through the streets.

troops marching through the streets.

automobile model, the first car made by automotive industry business.

noble person arrives in a car.

a family gathers around a christmas tree to celebrate western christian holiday.

Historical shooting of Morat in the presence of General Henri Guisan, Bois Domingue hill (June 21, 1942)

Spectators in traditional costume, Morat Historical Shooting (June 21, 1942), Bois Domingue Hill

photograph of a man holding a giant inflatable balloon.

bride and groom walking down the aisle.

Gathering of youth [sights], [Mort]

a group of children at a christmas party.

children playing on the shore of a lake.

a soldier stands in front of a crowd of people in front of a house.

a tree on a lake.

Commercially exposed refrigerators and washing machines [E. Joggi], Morat

football player with his team - mates before the match against football team.

Jakob Götschi, owner of the Brewery Helvetia, Morat

photograph of the entrance to the building.

Couple on boat trip to Rotary de Morat (29 June 1949), Yverdon-Yvonand

photograph of a group of men and women sitting on the deck of a ship.

a car parked in front of a building.

Terrace of the restaurant of the hotel Murtenhof, Morat

a display case in a shop window.

passengers on a train in the 1950s.

photograph of a group of women sitting in a living room.

reflections in a lake by visual artist.

Cortège de la Solemnité (21 June 1958), girls in white, rue Principale, Morat

wedding of person and noble person.

children reading books in a park.

children playing in the snow.

photograph of a group of young men standing in front of a piano.

Colonial Troops [French soldiers interned in Switzerland], [Morat]

Morat from the scaffolding of the German church

a group of boys pose for a photograph.

vintage photo of a man with his motorcycle.

Motocyclist and his moped Lampretta, rue Principale, Morat

Fisherman on his rowing boat, Lake Morat

Armaillis and wrestler at the wrestling festival, Morat (6 September 1941)

crowds at the opening ceremony.

actor in a scene from the film, directed by film director.

Coral player from the Alps during the historic Murat Shooting

Man on horseback, obstacle jump

Ancient mills of the city at the foot of the castle, Morat

Morat from the shore of the lake

Mount Vully and frozen lake seen from the snow-covered houses of Morat

children playing in a fountain.

School, children on the fountain of Bubenberg, Morat

Main Street and Bern Gate, Morat

House Rübenloch, Main Street, Morat

photograph of a group of young people standing in front of a stone wall.

photograph of a family sitting in a living room.

photograph of a street in the village.

Café "Zur Traube", rue Principale, Morat

Hans and Elisabeth Wildanger playing flute at home, Main Street, Morat

a christmas tree in the home of person.

Restaurant and baths at the foot of the castle, Morat

photograph of a group of seagulls.

photograph of a lake in the 1950s.

Former ditch bordering the ramparts, with the photography workshop (behind the Café du Nord), Morat

painting artist, portrait of a man.

photograph of a sailing boat.

photograph of a rocket being launched from a building.

photograph of a family sitting on a bench.

photograph of a gazebo by person.

photograph of a farmer and his cattle.

Replacing the statue of the Bubenberg fountain with a free copy of Willy Burla, Morat

Bern Gate under renovation, Morat

a photograph of a large tropical cyclone.

photograph of inventor at work in his laboratory.

photograph of a group of men taking a photograph.

Hydravion (Marcel Nappez) on Lake Morat, Vallamand

photograph of a man standing in front of a window.

photograph of the monument to person.

a black and white portrait of religious leader.

statue of builder on the cross.

a house.

late gothic revival structure in the early 1900s.

photograph of a traditional house.

actor in a scene from the movie.

photograph of a group of men walking in front of a building.

photograph of a woman and a man standing in front of a door.

a family gathering for western christian holiday.

photograph of a woman talking on the telephone.

women picking tea leaves in a plantation.

portrait of actor wearing a suit and tie, 1950s.

monarch and noble person looking out of a window.

children playing in the street.

women walking down a street.

Wedding of Emile Gardaz, columnist and writer, children picking candy

passengers board a train for filming location.

Woman laughing, [Fribourg]

a couple in a convertible car.

Couple at the exit of Saint-Nicolas Cathedral during a wedding, Fribourg

photograph of a couple walking down a street.

crowds of people in the streets.

monarch and noble person greet the crowds gathered for the wedding of noble person and noble person.

wedding of noble person and businessperson.

crowds gather outside the house of politician.

boys playing football in the streets.

a group of young people in a church.

Wedding, bride in a living room (with a TV), [Fribourg]

Children's Mass Servants and Bell Ringers, Fribourg
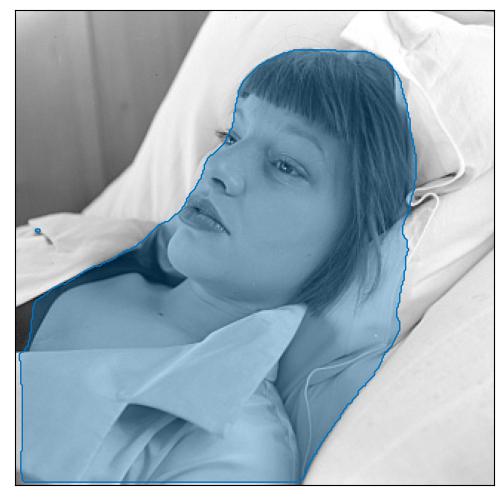
portrait of a young woman lying on a hospital bed.

a bride and groom on their wedding day.

woman walking on the street in winter.

wedding ceremony in the streets.

a group of people sitting in a car.

a group of men and women walking on a bridge in the 1950s.

noble person attends an event.

Married with assorted bridesmaids, Fribourg

politician and his wife at the wedding of person and noble person.

Men and women alcoholics at the Ball d'étudiants des Belles-Lettres, Fribourg
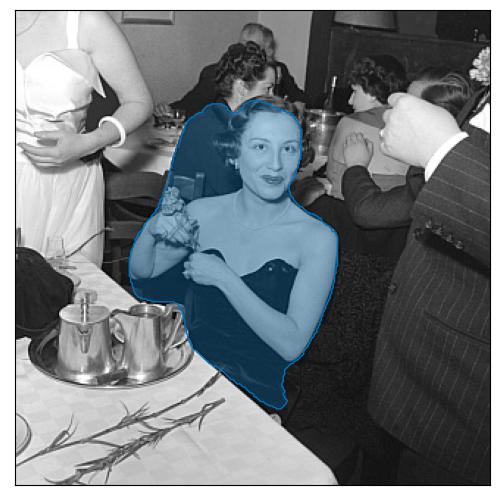
Marinette Brunschwig at an evening of the WIZO (Women's International Zionist Organisation), Fribourg

photograph of a family sitting at a dining table.

Two women at a costume party, [Paris]

a group of men stand in front of a flag.

Couple at a table at the international student ball, Café de la Glâne, Fribourg

Women around the buffet of the functionaries' ball, Fribourg

Michel Abriel celebrating the Eucharist at his first Mass, Villars-sur-Glâne

photograph of politician and his wife at an event.

crowds of people walking down the escalator in a scene from the film.

the wedding of religious leader and noble person.

actor in a suit and bow tie.

crowds gather to see psychedelic rock artist.

Married with assorted bridesmaids, Villars-sur-Glâne

Children (boys) in front of the Augustins during the first communion, Fribourg

politician addresses a large crowd.

dancing in the streets during the parade.

children playing in the street.

Armailli at rest (supported by a car) at the Poya d'Estavannens

a group of men and women working in a field.

children sing during a performance.

dancers perform in front of the hotel.

a group of young people look at a car.

monarch and noble person at the grave of person.

crowds of people on a motor scooter.

a priest speaking into a microphone.

actor and his wife attend an event.

politician and his wife are greeted by a crowd of people as they arrive.

a group of puppets dressed up for western christian holiday.

crowds gather for the wedding of person and noble person.

crowds at a rally for politician.

a nun shares a laugh with a nun.

a statue of religious leader.

a family in the 1950s.

Saint-Sacrement facing the Cathedral at the procession of the Fête-Dieu, Fribourg

monarch and noble person in a scene from the film, directed by film director.

a boy and his father with an elephant.

Children in armpits behind milk bottles, Gruyère

Pierre-Henri Simon and Gonzague de Reynold, professors at the university, during a meeting of the EJN, Cressier-sur-Morat

crowds of people on the beach.

African Student Congress at the University of Fribourg

politician shakes hands with a young girl at an event.

physicist at work in the laboratory.

soldiers receive a certificate of completion from politician.

crowds of people in the streets.

photograph of a crowd of people waving flags.

photograph of a sign for a city.

photograph of a nun in front of a painting.

demonstrators march through the streets.

demonstrators march through the streets.

photograph of politician driving a convertible car.

a group of children playing in the street.

crowds at a football game.

Fête fédérale des jodleurs, parade at Place Georges-Python, Fribourg

Federal wrestling party, combat wrestlers, Fribourg

Scouts gathered for Glaive Routier, activities in the Fribourg countryside

Scouts gathered (Glaive Routier) at the Planche-Supérieure, Fribourg

this is a photograph of the roof of a building.

Music-hall dancers at the Livio Theatre, Fribourg

Arlette Zola, singer, during a show by Radio-Lausanne, Grand-Places, Fribourg

Arlette Zola, singer, during a show by Radio-Lausanne, Grand-Places, Fribourg

ballet dancer on the set of musical comedy film directed by film director.

Nigerian Ballet at the Livio Theatre, Fribourg

young women dancing on the deck of a cruise ship.

photograph of politician addressing a crowd.

a group of young boys playing a game of mini golf.

a man rides a motorcycle through a field.

cyclists nearing the end of stage as it enters a city.

olympic athlete on his way to winning the men's road race.

photograph of a pilot standing next to an airplane.

ice hockey player, left, and ice hockey player, right, play a game of ice hockey.

a group of men clean up the water after a fire broke out.

Women in Sport Dress at CF Friboug's National League B Celebrations, 1952

Children's race (Summer-School), Avenue de Gambach, Fribourg

the team before the match against football team.

a man and a woman standing in front of a van.

photograph of a group of people working in a commercial kitchen.

a young woman and a young man reading a newspaper.

soldiers stand in front of a military vehicle.

a nun wearing a nun's veil.

a group of men and women sit on the steps of a building.

Course at the Institute of Zoology of the University of Fribourg

a group of men sitting at a table in a conference room.

students studying in the library.

members of the women's and men's teams at a dinner party.
Blood donation in the sports hall of the University of Fribourg
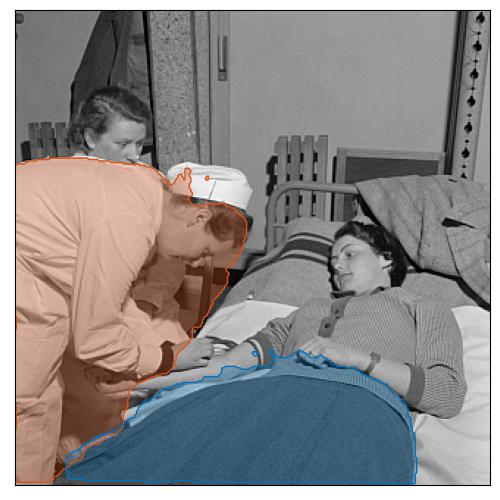
Nurse with a woman giving her blood, University of Freiburg

Blood donors eat in the locker room of the Society of fencing, University of Fribourg

visual artist at the exhibition of his work.

politician gives a speech at the graduation ceremony.

Man with a beer on the terrace of the Café des Arcades, Place des Ormeaux, Fribourg

photograph of workers in a factory.

a man working on a tractor.

scientists at work in a laboratory.

Brasserie du Cardinal, Fribourg

photograph of a group of men standing in front of a building.

a man standing in front of barrels of beer.

a group of workers in a factory.

Yard station from the Tower of the Brasserie du Cardinal, Fribourg

a tank on the road.

children playing in the back of a car.

automotive industry business on the road.

Child carrying wood, rue des Augustins, Fribourg

men digging a trench in a street.

construction of the - photo sharing!.

railroad tracks in the 1950s.

actor as film character and actor as film character in a scene from the film.

a vintage advertising poster in the town centre.

Information stand on nylon lingerie at the department store "Aux Trois Tours", Fribourg

Women in swimsuit at the baths of La Motta, Fribourg

a model walks the runway at the fashion show during fashion week.

models walk the runway at the fashion show.

Woman (model) wearing jeans, Fribourg

Female (Miss Switzerland 1953) in swimsuit, Fribourg

Female (Miss Switzerland 1953) in swimsuit, Fribourg

actors and film director

actor in a scene from the film.

a woman stands in front of a window with a man standing behind her.

a mother and her children in the streets.

photograph of a group of people sitting on a bench in a park.

boys on a scooter in the streets.

children playing in the street.

a woman selling ice cream in a street market.

a nun walks down a cobbled street.

a woman carries a bouquet of flowers.

person and actor on the street.

a man walking in the rain.

a group of children play in the snow.

Traffic Officer at Place de la Gare, Fribourg

Court of the University of Fribourg, site Mercy, with students

a family in the kitchen of their home.

a group of children sit at a table in the living room of their home.

a boy and a girl sitting on a snow - covered park bench.

men playing a game of dominoes.

photograph of a woman sitting at a table in a restaurant.

students sitting on a bench.

women working in a factory.

a group of children gather around a picnic table in a village.

crowds gather to watch the parade.

photograph of a group of people walking on a river bank.

a group of people walking along a lake.

Gas plant on the banks of the Sarine River (in flood), Planche-Inferior, Fribourg

horse and cart in the streets.

children playing in a swimming pool.

children play in the fountains.

children playing ice hockey in the snow.

Garage of the Bourg between the churches of Cordeliers and Notre-Dame, rue de Morat, Fribourg

Worker burying telephone cables, Fribourg

photograph of the funeral of military commander.

people waiting for the train.

a group of young people dancing on the street at night.

a baby in a pram.

person at work in the window of her bakery.

children playing in a boat on the beach.

tourist attraction in the rain.

soldiers with their families in front of a house.

children playing in a swimming pool.
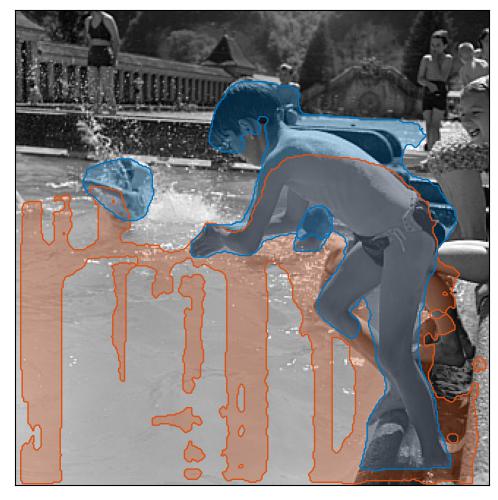
children playing in a pool.

a large crowd gathers for a meal.

crowds of people on the street.

actors and film director

photograph of a group of young people sitting in a car.

a man and a woman sit on a bench in front of a building.

children dancing in the streets.

a group of women dressed in traditional clothes, standing in front of a house.

portrait of a boy holding an easter egg.

monarch and noble person with a group of children.

little girls dressed as angels in a church.

people enjoying a picnic on the beach.

horse and carriage in the streets.

a boy on a donkey.

boys playing in the water.

photograph of a group of people sitting on the grass.

a group of boys sit on a bench in front of a fire escape.

portrait of an old man.

Baggage of pilgrims, Rome

Young pilgrims inside St. Peter's Basilica, Rome

Pilgrims on St Peter's Square, Rome

Two women sitting at the coffee table, Fribourg

soldiers sitting on a bench.

Horses at the breeding fair competition, veterinary inspection, Fribourg

a shop window in the neighborhood.

models walk down the runway at the fall fashion show during olympus fashion week.

workers on a construction site.

children play on a playground in the 1950s.

a man and a woman stand next to an elephant at a circus.

a man cooking food.

René Ribotel, ticket seller of La Loterie Romande, Avenue de la Gare, Fribourg

crowds line up to buy a car at a car show.

Sister (religious) of Saint Vincent de Paul, Fribourg

Women in conversation in front of the pipe shooting stand, Fête caraine des Grand-Places, Fribourg

a woman plays the accordion in the street.

photograph of a woman looking out of a window.

a family waits for the arrival of person.

a woman walking down the street.

Woman crossing the street (through the glass), boulevard de Pérolles, Fribourg

man with a bicycle in the streets.

a young girl and her mother cross the street in the 1950s.

soldier helping a wounded man in the streets.

Tour de Suisse (sports cycling), spectators at the Route des Alpes, Fribourg

portrait of a young woman sitting in a hammock.

children playing with a dog in front of a house.

a man sitting at a table with a cup of coffee.

an elderly woman smoking a cigarette.

Sleeping man in front of his glass at the closing of the bistro, Fribourg

children playing baseball in a park.

Children picking up a shoe, Grand-Rue, Fribourg

children playing in the playground.

Balconies of a house in the Auge district, rue des Forgerons, Fribourg

Sisters (religious) of Saint-Joseph de Cluny at the procession of the Fête-Dieu, Fribourg

Children around a "cinema machine" at Freiburg train station

a man sits at a table with a cup of tea and a cigarette in his hand.

Tour de Suisse (sports cycling), cyclists in front of the Ancienne Gare, Fribourg

a family gathers around a table in their living room.

Children in front of a window with an electric train model, [Fribourg]

a a barber at work.

Children singing on May 1, Fribourg

Newsstand and Morris column under the snow, George Python Square, Fribourg

Refurbishment of the roadway of Boulevard de Pérolles, asphalt workers, Fribourg

photograph of a man reading a book in a library.

a farmer with his horse and cart.

women picking potatoes in a field.

Two elderly men sitting on a bench at Place des Ormeaux, Fribourg

a group of soldiers in a parade.

soldiers take a nap in the shade of a tree during military conflict.

a woman walks through a snow - covered park.

children washing dishes in a wheelbarrow.

children playing in a park.

monarch riding a horse during the wedding ceremony of noble person and noble person.

shoes for sale in a shop window.

children playing in the street.

actor with his wife on the beach.

couples dancing on the deck of a ship.

portrait of a boy holding a box.

a butcher waits for customers at a market.

actor walking down the street in a scene from the film.

mother and children in a hospital room.

Cantonnier pushing his wheelbarrow at Rue de la Samaritaine, between 1940 and 1950

children playing in the street.

the toilet in the basement.

students in a classroom.

an old door in an abandoned building.
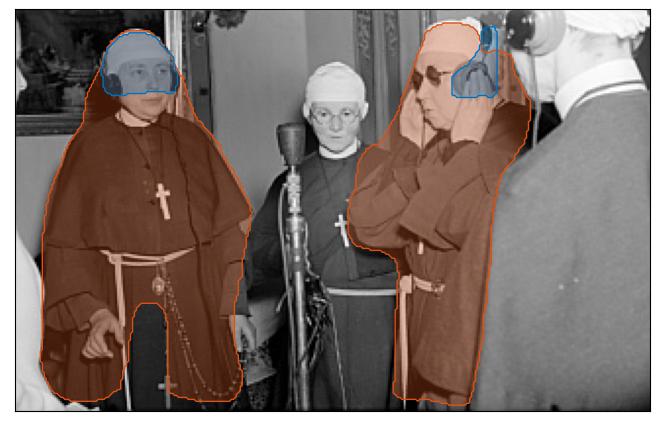
Sisters (religious) with headphones during the recording of a show by the Chaîne du Bonheur, Fribourg

Institute for young girls "Bon Pasteur", sister (religious) with a journalist, Villars-les-Joncs

politician at work in the kitchen of his family's home.

a church with a cross on the pulpit.

Romont primary school, coat rack

photograph of a family at a dinner table.
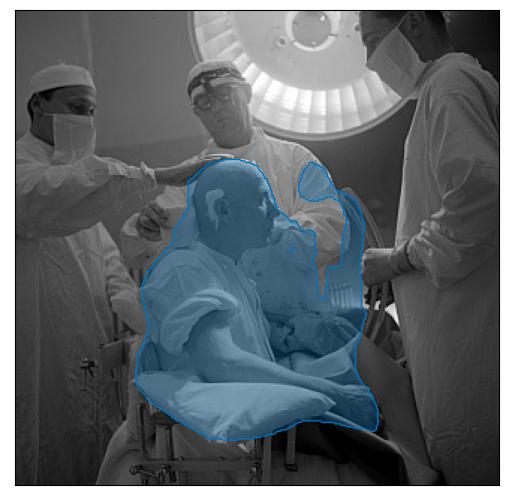
François Ody, neurosurgeon, practicing lobotomy at the Cantonal Hospital in Fribourg
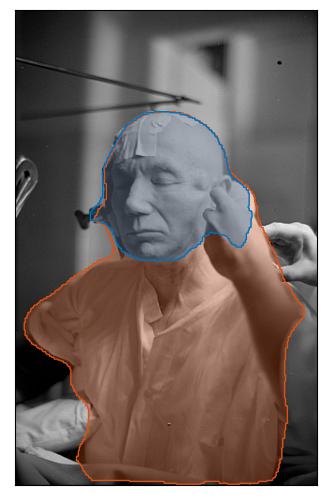
a model of the head of military commander is unveiled.

Cigarette collection organized by the Chaine du Bonheur for hospices for the elderly, Fribourg

automobile model in a muddy puddle.

a boy and a girl sitting on the steps of a house.

a group of soldiers sitting on a jeep.

painting artist in front of a painting by painting artist.

children playing in the street.

a man walking his dog on the street.

photograph of men standing in front of a house.

a street performer in the streets.

a man prepares food in the kitchen of his home.

soldiers relax on a park bench.

actors on the set of romantic comedy film directed by film director.

Dancer posing near the river, [Sarine]

Waiting room of the SBB train station, travellers in the early morning, Fribourg

Employee in the telephone booth maintenance service, Fribourg

Socialist posters against poverty and poverty in public premises, 1942-1945

a woman sits on a bench and reads a newspaper.

a man loading a cart with fruit and vegetables into a tractor.

a couple standing on the edge of a cliff looking out to sea.

men working on a river.

Scouts gathered for Glaive Routier, activities in the Fribourg countryside

Rallye de la Madone des Centaures, couple tied on the bike, Fribourg

photograph of a group of men standing in front of a car.

a group of people sit around a table in a restaurant.

a group of men playing a game of football.

a model prepares backstage at the fashion show during olympus fashion week.

Additional service for women (military vehicles), Caserne de la Poya, Fribourg

a young woman sitting on a park bench, reading a newspaper.

a man walks past a dog on a street corner.

Female nude (model of the Academy of Fine Arts), Fribourg

Female nude (model) in Robert Müller's workshop, Paris (France)

a rock climber climbs up a steep rock face.

black and white portrait of a young woman lying on the river bank.

actor in publicity portrait for the film.

Cabaret artist, Fribourg

Gasoline pumps and kiosk on the rue du Simplon, Fribourg

Living room of an apartment with a radio station, between 1950 and 1955

actor in front of a newspaper.

photograph of a horse - drawn carriage.

trucks and cars on the road.

Worker on a pole laying telephone wires

electricity pylons at a power plant.

a group of workers in a factory.

portrait of a young woman wearing a red dress and hat.

street vendor selling fish on the streets.

film director and actor on the set of the movie.

racecar driver at the wheel of his car.

a selection of vintage racing cars.

ice hockey right winger and ice hockey left winger.

Joseph Bovet at the organ of the Cathedral of Saint-Nicolas, Fribourg

Joseph Bovet leads liturgical songs at the Congress of Swiss Catholics, Grand Places, Fribourg

a group of students marching down a street.

Pins in Polish costume for "Four concerts for Polish orphans", Fribourg

children playing on a park bench.

photograph of a group of people in front of a house.

passengers boarding a train at the railway station.

photograph of a group of women standing in a park.

photograph of a young woman sitting on the edge of a mountain.

children playing in the street.

bridge over river in the town.

Grand store "Aux Trois Tours", Rue de Romont, Fribourg

Freiburg station, train on the wharf

Garage de la Gare (Spicher & Cie), former railway station, Fribourg

photograph of the bell tower.

construction of the bridge over river.

an old photograph of the restaurant.

a car is crushed under the weight of a building.

photograph of an apartment building at night.

Livio Theatre, rear façade, Arsenaux Road, Fribourg

Covered market, Comptoir Road, Fribourg

Young women at the Institut des Hautes Études at the Villa des Fougères, Fribourg, in 1950 and 1960.

Brasserie Beauregard and Saint-Pierre church, Fribourg

apartment buildings in the city.

a man on a tricycle crosses a bridge.

transit vehicle type crossing the viaduct.

Pont du Gotteron, construction of the wooden hanger, Fribourg

Pont du Gotteron, construction of the wooden hanger, Fribourg

construction of the new bridge.

construction of the cable - stayed bridge.

construction of the bridge over river.

Gotteron bridge, construction, formwork, Fribourg

tourist attraction in the 1950s.

soldiers with a christmas tree.

tanks pass through a city during a heavy snowfall.

soldiers on the bridge in the snow.

a group of people on a suspension bridge.

Gotteron bridge, construction, dismantling of the apron of the old suspended bridge, Fribourg

men standing on a bridge.

construction workers on the bridge.

crowds at the opening ceremony.

crowds wait for the arrival of politician.

politician waves to the crowd as he arrives.

rock climbing in the late 1800s.

photograph of men on a cable car.

a windmill.

Gotteron bridge, construction, dismantling of the cables of the old suspended bridge, Fribourg

Old bridge suspended from the Gotteron with ropes, Fribourg

Food Fair (15th), Place de Notre-Dame, Fribourg

smoke billows from a burning building.

crowds gather around the ruins.

a group of men gather around a fire in the camp.

a group of motorcyclists waiting for the start of the parade.

photograph of a group of young people in front of a house.

construction of a new housing estate.

crowds gather to watch the parade.

photograph of a group of children holding balloons.

a group of men and women jogging in a park.

a father and son playing kite in a park.

a little girl and a little boy walking down the street.

photograph of monarch and noble person holding hands in front of a crowd of people.

firemen on the scene of a fire.

Out of a water pipe, rue du Pont-Mure, Fribourg

smoke billows from a burning police car.

Repair work for a water main, rue du Pont-Mure, Fribourg

photograph of a shop in the district.

old house in the middle of the street.

a woman sleeping on a bicycle.

a man on a skateboard.

photograph of a bride and groom standing in the doorway of their home.

Pensioners of the home of Providence with a sister, rue de la Neuveville, Fribourg

Pensioners of the home of Providence with a sister, rue de la Neuveville, Fribourg

a group of boys reading a book.

astronaut in the classroom of his private school.

photograph of a man flying a kite.

Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg

crowds of people on the beach.

Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg

Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg

a group of children sit on the floor of a train carriage.

football team manager shakes hands with the players before the match.

children in a classroom.

cyclists at the start of the race.

automotive industry business in the streets.

crowds gather to watch the parade.

cyclists at the start of the race.

photograph of a group of people standing in front of a building.

the prince of wales receives a bouquet of flowers from a young fan.

photograph of a group of young people waiting for a bus.

boxer throws a punch at professional boxer during a boxing match.

crowds of cyclists and pedestrians cross the road.

Funeral of Jo Siffert (pilot car), rue du Pont-Mure, Fribourg

children playing in the mud.

a man selling newspapers in front of a car.

children playing in the street.

Rue de Romont decorated for Christmas parties, Fribourg

photograph of a man standing in front of a shop window.

photograph of a priest and a nun in front of a church.

actor with his family in a scene from the film.

photograph of monarch and noble person walking down the street.

a mother and her child buying food from a street vendor.

men selling potatoes at the market.

photograph of politician and his wife waving to the crowd.
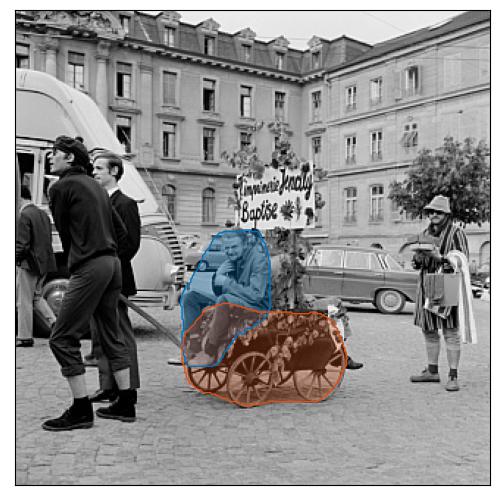
monarch and noble person in a horse drawn carriage.

a man washing his face in the street.

actors at a restaurant in the 1950s.

a group of men look at a painting by painting artist.

Ferruccio Garopesani, painter, in front of the store of Jean Mülhauser, rue du Pont-Mure, Fribourg

painting artist at work in his studio.

politician inspecting a statue of monarch.

photograph of politician and members of his cabinet at the conference hall.

politician, left, and politician, right, look at a drawing of politician during a meeting.

actors in a car in a scene from the film.

photograph of monarch and noble person talking to each other in front of a church.

photograph of a crowd of people walking down a street.

photograph of a man crossing the street.

crowds gather for the opening ceremony.

american football player sits on the grass with a camera on his shoulder.

american football team running back american football player is tackled by american football player during the first half of a football game.

baseball player throws a pitch during a game against sports team.

photograph of a farmer plowing a field with his tractor.

a group of men playing football in a field.

photograph of a group of women playing a game of kite.

crowds watching a game of cricket.

a group of young men and women playing a game of cricket.

a man jumps on a trampoline at festival.

a man jumps into a swimming pool.

a group of young people at a bar.

olympic athlete and olympic athlete in the swimming pool.

football player, football player, football player, football player, football player, football player and football player.

children jumping into a swimming pool.

a swimmer jumps into the water.

a group of children playing in a swimming pool.

dancers perform during the opening ceremony of festival.

a group of men and women stand in front of a building.

crowds gather to watch the parade.

military parade through the streets.

crowds line the streets for the funeral of military commander.

a group of priests standing in front of a church.

a group of men in white shirts walking down a street.

crowds of people walking in the rain.

crowds gather to watch the parade.

monarch and noble person attend the wedding of noble person and businessperson.

politician addresses the crowd at the dedication ceremony.

a group of young people walking down a street.

wedding ceremony of noble person and businessperson.

dancers performing on a stage.

dancers in a ballet class.

Satus (Fédération Ouvrière Suisse de Gymnastics et de Sport) at the Livio Theatre, Fribourg

Satus (Fédération Ouvrière Suisse de Gymnastics et de Sport) at the Livio Theatre, Fribourg

dancers performing in a scene from the film.

musicians in a scene from the film.

religious leader blesses the altar during his visit.

a group of children gather around a statue of military commander.

a crowd of people gather to watch a procession through the streets.

monarch and noble person at the opening ceremony.

monarch and noble person at the wedding of noble person and businessperson.

crowds gather to hear the announcement of the surrender.

a group of women reading religious text.

crowds gather to watch the parade.

a group of people walking on the street.

soldiers resting in a field.

photograph of a woman walking on the beach.

soldiers marching in the streets.

soldiers resting in a forest.

a group of soldiers jumping over a tree.

photograph of a large group of soldiers standing in front of a large building.

workers dig a trench on a street.

photograph of a man carrying a cardboard box.

tourist attraction in the 1950s.

a worker welding metal on a construction site.

construction of the new bridge.

Schiffenen Dam, construction, workers and wheelbarrow suspended

Schiffenen Dam, construction of the plots from the right bank, general view

photograph of a group of people standing in front of a large bell tower.

photograph of politician addressing a crowd.

Schiffenen Dam, construction, uphill view

fireworks explode from the deck of ship.

construction of a new bridge.
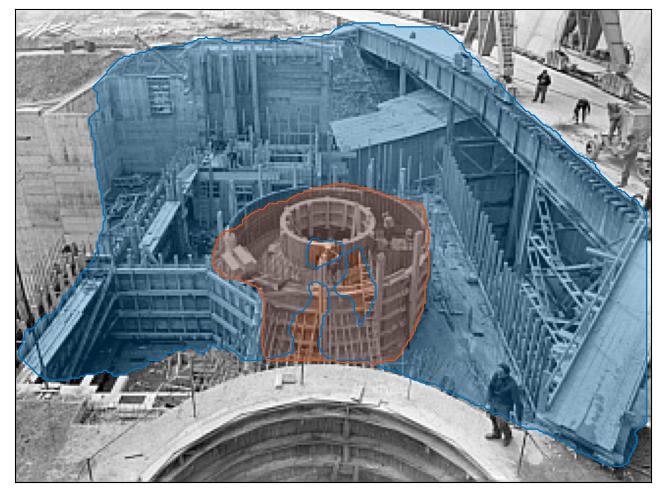
Schiffenen Dam, construction of hydroelectric power station

Schiffenen Dam, construction, lake and dam upstream, fishing children

mountain range in the distance.

men working at a construction site.

Rossens Dam, construction, preliminary works (protection dam)

a group of men working on a construction site.

photograph of a group of men working on a rock formation in the desert.

a group of men climbing up a steep rock face.

a group of miners working in a mine.

a group of workers in front of a fire engine.

Rossens Dam, construction, workers around wagons

a group of men sit on a bridge.

actor in a promotional photo for the film.

a group of people in front of a cross.

men working on a new bridge.

construction of the bridge over river.

construction of a bridge over river.

men working on the roof of a house.

a train on the tracks.

tourist attraction in the 1930s.

tourist attraction in the 1930s.
a plant growing through a hole in a brick wall.

construction workers on the ship.

a bus stopped at a gas station.

a group of construction workers building a house.

construction cranes at a construction site.

photograph of a man lighting a cigarette.

silhouette of a man jumping over a bridge.

photograph of a man standing in front of a water tank.

a young boy with a chainsaw.

black and white photo of a house submerged in water.

monarch and noble person at the opening ceremony.

crowds line the streets to watch the parade.

cars lined up at the start of the race.

construction of the tower, ca.

Rossens Dam, construction, workers laying on a drain line

Rossens Dam, construction, drain line

Rossens Dam, construction, filling of vertical joints

Rossens Dam, construction, rise of water and formation of Lake Gruyère

Rossens Dam, construction, rise of water and formation of Lake Gruyère

water reservoir lake in the 1930s.

construction workers on a construction site.

painting artist at work on the ceiling of his studio.

bridge over river in the 1950s.

suspension bridge in the fog.

a a man walking past a concrete wall.

construction of the - photo sharing!.

construction of a new underground tunnel.

Dam of the Maigrauge, expansion of the Oelberg plant (indoor view), Fribourg

the crew of the first nuclear - powered submarine.

a soldier stands guard at the entrance.

Dam of the Maigrauge, expansion of the Oelberg plant, Fribourg

women working at a construction site.

monarch and noble person arrive for the wedding ceremony of noble person and businessperson.

photograph of a crowd of people walking down a street.

Church of Christ-Roi, construction, boulevard de Pérolles, Fribourg

photograph of politician shaking hands with politician at an event.

a little boy and his father in the streets.

actor and his wife attend an event.

dancing at a wedding reception.

noble person at an event.

actors on the set of romantic comedy film directed by film director.

the wedding of actor and person.

a group of people dancing in the snow.

Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey in the crowd, Fribourg

a group of young people dancing in the street.

religious leader praying in a church.

a group of young people dancing in the street.

Sale of biscômes at the market of the Feast of Saint-Nicolas, Place de Notre-Dame, Fribourg, 1959

photograph of a crowd of people standing in front of a stage.

Cortège de la Saint-Nicolas, torchbearers, Fribourg

people buying sweets at the market.

a group of men lighting a fire in the dark.

actors in a scene from the movie.

a group of children dressed as soldiers stand in front of a building.

Cortège de la Saint-Nicolas, Saint Nicolas and Father Fouettard on the balcony of the cathedral, Fribourg

film character in a scene from the film.

Cortège de la Saint-Nicolas, crowd from the cathedral balcony, Fribourg

photograph of a street vendor in a supermarket.

photograph of a woman looking at clothes in a shop window.

street market in the old town.

photograph of a stall at a market.

flowers for sale at the flower market.

a woman selling balloons at a street market.

transit vehicle type in the 1950s.

Cantonal festival of Fribourgeois music, Morat

actor in a white dress.

photograph of actor at a formal event.

olympic athlete and olympic athlete at the start of the race.

photograph of the football team.

photograph of military commander and person.

crowds at the start of the race.

a group of cyclists stand in front of a building with a sign saying.

photograph of a family sitting on the porch of their home.

photograph of military person wearing a military uniform, standing in front of a marching band.

crowds gather to watch the parade.

photograph of the wedding of politician and person.

actors in a scene from the movie.

Jardin des Grand-Places, inauguration offered by the Rotary Club, Fribourg

tourist attraction in the 1950s.

politician greets the crowd during his visit.

photograph of workers in a shipyard.

olympic athlete competing in a match with olympic athlete.

soldiers pose with an airship during military conflict.

a group of soldiers stand in front of a line of fire.

a group of soldiers pose for a photo.

troops marching through the streets.

a little girl and a little boy holding a christmas tree.

photograph of a house in the 1920s.

monarch and noble person at the ceremony.

a woman withdraws cash from an atm machine.

Teaching of the Café du Tunnel, Fribourg

a narrow street in the old town.

Pedestrian passage towards Rue de Romont, with the temple, Fribourg

a building.

a building.

La Placette supermarket shop, Fribourg

a street scene in the old city.

people crossing the street.

late gothic revival structure from the south.

snow on a tree in winter.

crowds of people crossing the street.

construction of the new building.

soldiers march through the streets.

men working on a rock wall.

Skier jumping, Moléson-sur-Gruyères

mountain range in the background.

one of the old trams.

sailboats lined up at the start of the race.

person in the production of eggs.

electricity pylons in the sky.

men working at a metal factory.

early stage construction of a villa featuring the car port.

a train crosses the viaduct.

group of people walking in a field.

kids playing in the snow.

sunrise over a lake in the countryside.

crowds gather to watch the opening ceremony.

sausages on a conveyor belt.

cooking in the 1950s, photo by person.

the assembly line at the factory.

a tractor ploughing a field.

trucks loading and unloading cargo at the port.

digital art selected for the #.

Elderly woman with a child in front of a farm, Guin

Vignes in the Vully

Farm and tobacco dryers, Broye District

a man on a tractor in the 1950s.

potatoes are loaded onto trucks at the plant.
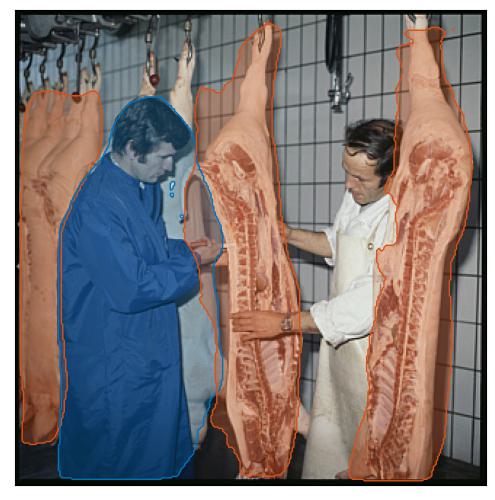
Micarna factory, butchers with carcasses, Shortepin

a field of sunflowers under a blue sky.

a farmer ploughs a field with his horse - drawn plough.

a man carries a bag of flour on his shoulder.

photograph of politician at a meeting.

photograph of politician at a desk.

photograph of politician shaking hands with a crowd of people.

monarch and noble person in the audience.

photograph of politician shaking hands with politician at an event.

Bakery, Fribourgeois specialities: cupcakes, cuchaule, wonders, anise breads, benichon mustard, croquets, lady's thighs

portrait of a girl in the snow.

Exit from the A12 motorway at Rossens at the nightfall

The Gruyère viaduct on the A12 motorway, Pont-en-Ogoz

teacher and students in a classroom.

a family picnic in the woods.

Armailli in front of a bell window, Gruyère district

portrait of a man with a cowboy hat.

a group of children dressed in kilts.

crowds of people at the market.

people eating at a restaurant.

painting artist at work in his studio.

a man with glasses smiling.

Emile Angeloz, painter, in his workshop, Fribourg

Ferruccio Garopesani, painter, in his workshop, Fribourg

a stained glass window depicting the life of military commander.

a woman working on a sewing machine.

Bruno Baeriswyl, painter, in his workshop, Fribourg

photograph of a group of women preparing food in a kitchen.

Professional Centre, Fribourg

sign on the door of a train station.

photograph of a man getting into a car.

automobile model at the car show.

actor on the set of musical comedy film, directed by film director.

members of the hockey team pose for a team photo.

photograph of a bus stop.

black and white portrait of a senior man.

ice hockey right winger poses for a portrait.

sports team pose for a team photo.

a bouquet of poppies, roses and daisies.

crowds linethe streets to welcome the new year.

flowers and candles are placed at the grave of person.

crowds gather to watch psychedelic rock artist perform on stage.

blues artist performs on stage with a crowd of screaming fans.

a man lying on the grass in a park.

photograph of a group of men standing in a snow - covered street.

actors in a scene from the movie.

demonstrators march through the streets.

a young boy stands on the side of a railroad track with his hands in his pockets as he waits for the train to pass.

crowds line the streets for the funeral of military commander.

photograph of a man reading a newspaper.

a woman holds a bouquet of flowers in front of the building.

crowds of people waiting for the arrival of the pope.

monarch and noble person during a visit.

a child looks through a pair of binoculars.

sculpture by visual artist in the grounds.

photograph of a woman working in a factory.

actor in a dress by film costumer designer.

transit vehicle type in the streets.

people buying fruit and veg at the market.

a shopper walks past a display of chocolates in a supermarket.

people shopping in a supermarket.

photograph of people shopping in a supermarket.

actors

posters for sale in a shop window.

bottles of beer on a shelf in a bar.

digital art selected for the #.

models backstage at the fashion show during olympus fashion week.

photograph of the building at night.

photograph of a woman walking in the street.

Traffic officer at Avenue de la Gare, Fribourg

photographer in a field with binoculars.

sculpture in the church of person.

University of Mercy, Fribourg

people crossing the street.

Bus stop from the train station, Fribourg

Bus stop from the train station, Fribourg

construction of the new building.

photograph of a building in the district.

Staircase of the Court-Chemin, Fribourg

a tree.

the building.

Bulliard building on St-Pierre Street, Fribourg

Migros Shop, Rue St-Pierre, Fribourg

photograph of workers in a factory.

a sign on a railway station.

photograph of a woman sitting on a chair in an empty room.

an old typewriter.

actors on a bicycle in a scene from the film.

pedestrians wait for a bus.

actor on a chair in a scene from the film.

photograph of men drinking beer in a bar.

photograph of politician at a luncheon.

actors

actor and his wife, enjoy a meal at a restaurant.

a group of teenage girls sitting on the steps of a house.

actors in a scene from the movie, directed by film director.

photograph of a woman wearing a hat and holding a glass of champagne.

actors on the set of romantic comedy film directed by film director.

monarch and noble person at a garden party.

politician waves to the crowd.

photograph of a crowd of people walking down a street.

actor dances with actor in a scene from the film.

Marriage

a couple in an open - topped car.

photograph of a group of people standing in a row in a factory.

blues artist performs on stage.

photograph of a group of young people dancing in a club.

actors in a scene from the movie, directed by film director.

a dining room.

dancer on the set of musical comedy film, directed by film director.

Advertising for Majorica beads (woman)

person and actor on the set of tv teen drama.

actor on the couch in a scene from the film.

person at work in the brewery.

newspapers from around the world.

photograph of workers in a factory.

photograph of a man climbing a ladder.

photograph of workers in a factory.

a group photograph of the women's volleyball team.

a man cooking in his kitchen.

a sign.

looking up at the building.

photograph of a man working at a sewing machine.

Man with statue at the Museum of Art and History, Fribourg

Man with statue at the Museum of Art and History, Fribourg

black and white portrait of a young woman.

painting artist as a child.

a close - up of a woman's hand holding a feather.

this is a photo of a lemon and honeycomb in a glass vase, taken by person.

a selection of chocolate chip cookies.

woman washing dishes in the kitchen.

a boy looking out the window of a steam train.

vendors at a market in the old town.

a woman selling vegetables at a market.

a traditional hat on display at festival.

a woman buying cheese from a stall at the market.

a woman walking down a dirt road in a village.

teenage boy and girl sitting on a bench in the mountains.

Mechanical lifts (telepherical) from Moléson, Moléson-sur-Gruyères

snowboarder and person on the slopes.

soldiers stand in front of the control tower.

Fashion show at the Eurotel organised by the boutique Gambetta, Montreux

person and groom walking down the stairs.

photograph of workers in a factory.

actor in a suit and tie, 1950s.

martial artist poses for a portrait.

cattle being judged at a rodeo.

portrait of a girl with her brothers and sisters in the background.

children playing on a beach.

a man standing in front of a bus stop.

photograph of a man and a woman in a chemist shop.

vintage air balloon in the shape of a heart.

actor with a towel on her head.

a family walking through a forest.

the statue of person by visual artist.

the dining room.

the stairs leading up to the second floor.

statue of person in the church.

# of the basketball team poses for a portrait.

portrait of a woman sitting at a desk.

cheeses on a plate with a knife and fork.

students working on a computer.

a church in the city.

Building in Beaumont, Fribourg

the building, designed by architect.

photographer on the road by photographer.

a train at the railway station.

the production line at the factory.

aircraft model being loaded onto a plane.

Advertising for Cardinal beer with a woman

a man walks through a tunnel.

flowers in front of a door.

automobile model in the garage.

a man walking on a treadmill in a subway station.

Léo Hilber at work for the Museum of Art and History (MAHF), Fribourg

Advertising of the Fribourger stand at Placette (Manor) in Fribourg: children eating an American meal (frites, hamburger, soda)

Advertising of the Fribourger stand at Placette (Manor) in Fribourg: children eating an American meal (frites, hamburger, soda)

little girls getting their hair done at a hairdressing salon.

musical group perform on stage in a scene from the film.

monarch and noble person in the church.

visual artist in the workshop of visual artist.

Beaumont district from the construction site of Polytype SA, Fribourg

soldiers march through the streets.

Factory Chocolate Villars, Fribourg

a child plays with a potter's wheel.

Portrait of a young peasant, Broye

politician addresses the crowd at the opening ceremony.

Female employee of the company Milco SA checking the stocks of yogurt, Sorens

the basketball team poses for a team photo.

photograph of the wedding of person and noble person.

sculpture of a man and a woman.

photograph of a group of women seated in a bus.

photograph of a street scene.

person with his horse in the barn.

photograph of a group of women in a forest.

horse - drawn carriages in the streets.

a group of people sitting around a table in a garden.

Jaeger family with tennis rackets (with friends)

musical artist with his orchestra.

photograph of musicians in a recording studio.

photograph of a group of men and women.

children in front of a pharmacy.

crowds at the opening ceremony.

painting artist with his work.

a tram in the streets.

photograph of a group of men walking down a street.

the grave of military commander.

a woman sits on the porch of her home.

photograph of a young woman riding a horse.

a group of men sitting on a bench.

photograph of a woman holding a chicken.

monarch as a young woman.

a group of women working in a village.

photograph of a man and a woman standing in front of a house.

photograph of a snow - covered roof.

horse drawn carriage in the old town.

architectural details of the building.

a statue of military commander.

photograph of an old building.

one of the many churches.

stained glass window depicting the crucifixion of builder.

a replica of a 19th century gothic door.

cricket team pose for a team photo.

photograph of a group of uniformed officers.

photograph of members of the royal family.

photograph of a large group of people in front of a large factory building.

photograph of a cow grazing in the mountains.

photograph of a group of school children.

photograph of a crowd of people waiting to board a train at the train station.

photograph of a group of men and women.

suspension bridge in the 1930s.

Mountain chalet (16th century), Charmey

photograph of a group of men climbing up a mountain.

photograph of a group of people.

photograph of a group of men and women standing in front of a house.

photograph of a group of soldiers standing in front of a row of trees.

transit vehicle type in the 1920s.

photograph of a group of children.

a group of people in front of the church.

photograph of a horse and cart.

photograph of a group of people in front of a building.

photograph of a group of people.

photograph of a crowd of people.

photograph of a family walking in the woods.

photograph of a building in the area.

photograph of a woman working in a kitchen.

photograph of a crowd of people waiting to cross the street.

photograph of a group of soldiers.

photograph of a crowd gathered around a church.

photograph of a group of people marching in a parade.

photograph of a group of children.

photograph of a group of people.

photograph of a group of women dancing.

photograph of the dining room.

photograph of the dining room.

photograph of a group of boys and girls.

photograph of a herd of cows grazing in a field.

photograph of a group of people standing in a field.

poster for the funeral of person.

photograph of a man standing in front of a building.

photograph of a burning building.

photograph of a water pump.

photograph of a man standing in front of a fountain.

a group of men and women with bicycles.

photograph of a family standing in front of their house.

portrait of a young woman.

family portrait of a family.

portrait of a girl with her dog.

arch bridge in the late 19th or early 20th century.

Red Tower, Fribourg

a woman sitting in a car.

Man perched on the Viaduct de Grandfey, Fribourg

photograph of a wagon loaded with hay.

photograph of a group of men.

photograph of members of the team.

photograph of a woman playing a flute.

Subway from Freiburg train station, Beauregard side

a group of soldiers in front of a motorcycle.

children playing in the water.

photograph of a group of women.

photograph of a man working at a sewing machine.

photograph of an airship flying over a building.

photograph of a man standing in front of a shop window.

olympic athlete in action during a training session.

children playing in a canal.

employees working in a factory.

painting artist at work in the studio.

photograph of a family in front of a gas station.

an old typewriter.

construction of the new building.

photograph of a group of people in front of a shop.

crowds gather to watch the parade.

Works prior to the construction of the cantonal and university library at the top of the Varis, Fribourg

monarch and noble person in front of the cathedral.

photograph of a group of musicians holding a guitar.

a group of women and children in a laundry room.

photograph of a group of men and women seated around a table playing a game of football.

photograph of a group of men in suits and ties.

photograph of a group of people in front of a house.

a family portrait of the family.

photograph of the baseball team.

monarch and noble person celebrate the wedding of noble person and businessperson.

photograph of a group of men in uniform.

photograph of a group of musicians.

photograph of a group of men sitting in front of a house.

a group of men and women pose for a group shot.

a group of men standing in front of a brick wall.

photograph of a group of soldiers.

photograph of a crowd of people.

suspension bridge in the 1930s.

photograph of a group of people in front of a building.

a house.

a portrait of a man dressed as a clown.

politician and his wife pose for a portrait.

photograph of a woman working on a sewing machine.

Blessing Mass of Landsturm troops at Viaduc de Grandfey, Fribourg

soldiers riding in a jeep.

cars lined up on a street.

a man stands in the snow.

photograph of a man standing in front of a snow - covered tree.

a a horse - drawn carriage.

Bains du Boulevard ou Bains Galley, Quartier d'Alt, Fribourg

photograph of a medical practice.

nurses working in a hospital.

employees working in a factory.

photograph of a group of men working in a workshop.

monarch and noble person with a group of children.

men loading a fire engine onto a truck.

photograph of a young girl holding a sword.

Freiburg train station, Beauregard side

photograph of a group of musicians.

the wedding of noble person and businessperson.

photograph of a group of people.

photograph of a landscape with mountains in the background.

tourist attraction in the 1930s.

a man standing next to a car.

tourist attraction in the 1930s.

person, a sculptor by profession, stands next to his work.

Abattoirs of the city of Fribourg (Varis), suspended carcasses

a group of men and women standing in front of a fire engine.

photograph of men standing in front of a ruined building.

tourist attraction in the 1930s.

Hairdresser Antoine Huber, Rue de Lausanne 88, Fribourg

a portrait of religious leader.

cantilever bridge in the 1930s.

Livestock market at the Planche-Supérieure, Fribourg

tourist attraction in the 1930s.

Inauguration of the Zaehringen Bridge, Fribourg

crowds gather for the funeral of military commander.

ruins of the old town.

Hotel Terminus (Zaehringenhof), entrance, train station avenue, Fribourg

construction of the new stadium.

a a man walking along a river.

Livestock Fair, Grand-Places, Fribourg

people waiting for the ferry.

tourist attraction in the early 1900s.

drawing of the building by person.

a man stands in front of a building.

Collège Saint-Michel, Fribourg

politician and his wife in a horse drawn carriage.

Beating of the Grandfey viaduct, Fribourg

General meeting of the Swiss Student Society, Place Georges-Python, Fribourg

a train passes through a city.

Funicular workers linking the Neuveville district to St-Pierre, Fribourg

soldiers in front of a building.

Renovation work at the Pont du Milieu, Fribourg

Traffic on Rue des Bouchers, Fribourg

Traffic at the rue du Pont-Mure, Fribourg

Cantonal Psychiatric Hospital (Overview), Marsens

portrait of a young man.

a man with a mustache.

photograph of a group of people sitting in a car.

Sodalitas Labour City Housing Building, Rue des Cliniques, Fribourg

tourist attraction in the 1930s.

Fribourg (Sarine), Rue Saint-Pierre Canisius 10/20, Collège Saint-Michel (1582), former gymnastics hall, outdoor [Katholiken Tag]

portrait of a boy and a girl.

photograph of a group of men and women seated in a wheelbarrow.

photograph of a man working in a laboratory.

ducks swimming in a river.

photograph of a family with their dog in front of a house.

photograph of politician walking down the street.

photograph of a group of soldiers.

Inauguration of a commemorative plaque (regiment 7), Place Notre-Dame, Fribourg

photograph of a man with his horse and cart in a village.

crowds gather to watch the parade.

crowds gather to see the unveiling of the new school building.

photograph of a group of men working on a machine.

photograph of politician walking down the street.

photograph of a group of people working in a field.
crowds gather to watch the parade.
painting artist in his studio.
portrait of a man sitting on a bench.
Male (Hermann Nussbaumer) with his bike
women standing in front of a church.
photograph of a group of women sitting on a bench.
photograph of a family with children.
Music Society
steam locomotive pulling a passenger train.
photograph of a group of men and women seated around a table.
a group of men working on a swing set.
photograph of a house with a horse and carriage.
Stone bridge with diligence, Wünnewil-Flamatt
Castle of Ueberstorf (Ratzé), Sancta Maria Institute (boarding for girls)
portrait of a man with a beard.
Portrait of the wife of Mr Baeriswyl in the company of another young woman, Fribourg
Portrait of a young couple on their wedding day, [Fribourg]
Miss Ida Maurer in her uniform at the boarding school in Orsonnens, [Fribourg]
politician as a young woman.
portrait of a girl and a boy.
monarch and noble person pose for a family portrait.
tourists on a boat at night.
photograph of politician and his family.
portrait of a girl and a boy.
Jean Ramstein, son, in military uniform during the occupation of the borders during the First World War [Fribourg]
Forgerons en car in front of the store, employees of Mr. N. Cotting successor of Théobald Berguin, [Rue de Morat 246 (Act. No. 47), Fribourg]
portrait of a young man standing in front of a house.
Shop "A la Ville de Paris", Rue de Lausanne, Fribourg
Shop "Modes Chapellerie J.M. Meier", Rue de Romont, Fribourg
the wedding of person and noble person.
Portrait of a child, Fribourg
photograph of a group of men standing in front of a flag.
politician with his wife and their children.
photograph of a group of boys standing on top of a mountain.
Boat trip on Lake Morat
Picnic between women during military manoeuvres, Granges-Paccot
photograph of the swimming pool.
photograph of a group of people in front of a building.
a medical team working in a hospital.
actor in a scene from the film.
Fountain of the Force, rue de la Neuveville, Fribourg
Fontaine Sainte-Anne, Place du Petit-Saint-Jean, Fribourg
a man with a beard.
a man carrying a load of hay on his head.
statue of person in the church.
the wedding of noble person and businessperson.
Chartreuse de La Valsainte, cell of a monk, Cerniat
Fribourg from the Grand-Places
portrait of a young boy.
monarch and noble person in the cloisters.
portrait of a little girl.
tourist attraction in the past, history.
Houses in the town of Kippel, Lötschental (Valais)
children playing in the street.
Fisherman repairing his net
Capuchin Brother in the Church of the Count of the Capuchins, Fribourg
Gruyères, its castle and Moléson from the east
close - up of a woman's hands embroidering clothes.
portrait of a young girl.
person in the kitchen of her home.
Sisters of Providence caring for a child, Fribourg
a man playing with pigeons.
Sister of Providence reading to children, Fribourg
a fisherman.
ruins of an old castle.
Fileuse and its wheel, [Fribourg]
a statue of builder in a church.
a group of children playing in the courtyard of a house.
a roof.
a man works on the roof of his house.
Joseph Bourqui, "Biscuit" (1891-1959), Fribourg
a cowboy on his horse in the mountains.
Sarine, the river in winter near Fribourg
composer playing the organ at the organ.
religious leader blesses a child during his visit.
religious leader blesses a child during his visit.
Promenade de Monsieur le Curé, Lötschental
children playing in the mud.
Peasant repairing his fake, [Fribourg]
children planting a tree in the garden.
a flock of sheep in the mountains.
a young girl feeding chickens on a farm.
a young girl and a boy sitting on a bench in a garden.
a priest blesses a child during a mass.
photograph of a family in their living room.
a cow and her calf in a field.
monarch and noble person celebrate the wedding of noble person and businessperson.
a farmer ploughs his field with a horse and cart.
painting artist, portrait of the artist.
religious leader blesses the altar during a mass.
Door and corridor (with crucifix) of the Visitation convent, Fribourg
photograph of soldiers sitting at a table.
Little boy drinking milk in the mountains, [Fribourg]
Children on their way to school (countrypath)
Singaporean campaign
a farmer ploughs a field with his oxen.
Child (little girl) sewing in front of an old decorated wardrobe, Wünnewil-Flamatt
soldiers on a mountain ridge.
a young boy in a straw hat sits on a wooden cart pulled by a tractor.
Hatlet in a Fribourgeois peasant family
soldiers working in the field.
black and white photo of a truck driving along a dirt road.
photograph of politician at his desk in his home office.
Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey on the road to the Alps, Fribourg
Students in theology and religious at the University of Fribourg
Child with a ball, Fribourg
Foreign students visiting the University of Fribourg, site de Miséricorde
a man riding a bicycle in the woods.
children playing in the street.
children playing in the street.
a a man looking out over a city.
the skeleton of a dead man.
The city of Fribourg seen from the sky
Monsignor Paul von der Weid during the Fête-Dieu, Place Notre-Dame, Fribourg
mountain range in the 1950s.
Roof picker, [Fribourg]
Barques in a harbour, [Rhin]
dandelion seeds blowing in the wind.
suspension bridge over the river.
flowers on a window sill.
street in the old town at night.
a group of men stand in front of a snow - covered car.
Men (silhouette) on the stairs of the Court-Chemin, Fribourg
a photograph of a woman dancing in front of fireworks.
automobile model on the road.
a student working on a computer in the library.
Portrait of Georges Python, University of Fribourg
Ferpicloz, Sarine, Reformed German School, opened in 1862, closed in 1970
Granges-Paccot
Hotel de la Croix-Blanche, Treyvaux
Châtillon, from the south, Broye
Pensionat du Sacré-Coeur, Estavayer-le-Lac (Switzerland), dormitory and toilet
Households, general view
Montagny-la-Ville
Montagny (canton of Fribourg, Switzerland), church and tower
Montet (Fribourg), church and main street
the church in the village.
the statue of person in front of the church.
aircraft model in the field.
Château de Surpierre
photograph of a farm in the 1930s.
photograph of a farm in the 1930s.
Mézières (Fribourg), school and dairy
Torny-le-Little, the church
photograph of a group of women working in a classroom.
Romont, the castle
Romont, the casino
Torny-le-Grand
person and his wife, in front of their home.
Gurmels
photograph of a house in the neighborhood.
photograph of a village in the mountains.
Bull and the Gruyerian Alps
Dam of the Jogne and water intake at Châtel-sur-Montsalvens, [near Charmey]
Château de Corbières
Echarlens (Gruyère), general view and Gremaud bakery
Entrance to the Château de Gruyères
Psychiatric institution of Marsens/Gruyère, aerial view
Pont-la-Ville
Riaz - District Hospital
The Rock
photograph of a woman looking at books in a library.
photograph of a nun in the kitchen.
a man with his dog on a street.
Pensionnat St-Joseph, Gouglera near Eichholz (Ct. Fribourg), [comune Giffers]
church in the village of person.
Hotel Pension Alpenklub, Planfayon, [Plaffeien] (Ct. Fribourg)
Fliegeraufnahme von Schmitten/Frbg
Ueberstorf
Fribourg, Champ des Targets, Café des Chemins de fer, Ls. Cottage, prop. Tel. 1050, [Perolles]
Pensionnat de la Providence, Fribourg, Study room, [Neuveville]
Fribourg, baths and sports park of La Mottaz, [Neuveville]
photograph of a young girl standing in front of a building.
Fribourg, baths, [Neuveville]
painting artist on the banks.
The great cantonal pilgrimage of 24 September 1933 to the miraculous Virgin of Bourguillon
soldiers of the march through the streets.
tourist attraction in the 1920s.
troops march through the streets.
a group of soldiers stand in front of a building.
[Fête-Dieu 1914 - Fribourgeois regiment in the courtyard of the Cordeliers at the Mass said by Monsignor Hubert Savoy]
soldiers in front of a cannon.
crowds gather in front of the building.
soldiers on horseback in front of the building.
photograph of a group of men sitting in a car.
General Pau en Gruyère (12 June 1917)
photograph of a group of people standing in front of a building.
horse and cart in front of a house.
transit vehicle type in the 1930s.
photograph of a group of boys and girls standing in front of a school bus.
photograph of a group of people standing in front of an airplane.
Remains of the aircraft piloted by Léon Progin, following a fatal accident in Menziswil
aircraft model was the first aircraft to enter service.
photograph of a group of soldiers.
Official map of the Second General Congress of Swiss Catholics : IIer Schweizerischer Katholikentag : Fribourg, 22-25 September 1906
religious leadership title in the crowd.
photograph of military commander inspecting troops.
crowds gather to watch the procession.
monarch and noble person at the wedding of person and noble person.
monarch and noble person at the wedding of person and noble person.
photograph of a horse - drawn carriage.
Fribourg - University
photograph of a group of men with a horse and cart.
photograph of a family in front of a house.
photograph of a farmer with his cow.
a boy with a horse and cart.
painting artist, landscape with a family.
men with a horse and cart.
photograph of a group of men drinking beer in a restaurant.
father and son in the countryside.
pilgrims gather for a mass.
crowds of people on a horse - drawn carriage.
children in a car decorated for western christian holiday.
women in traditional dress marching in a parade.
troops marching through the streets.
photograph of a group of young people.
railway station in the 19th century.
horse - drawn carriages in the streets.
Bulle, the workers' houses (new quarter)
photograph of the entrance to the chapel.
photograph of a group of women standing in front of a building.
photograph of a man standing on the roof of a building.
Billens and Romont Hospital
ski area showing snow as well as a small group of people.
swimming pool in the mountains.
painting artist, illustration for the story.
photograph of a man riding a horse.
crowds gather at the start of the race.
Bulle Castle
rail transport business in the 1930s.
Modern hotel in Bulle
St Denis Fair in Bulle
St-Denis Fair in Bulle
Bulle, St-Denis Fair
a large tree on the side of the road.
Bulle, the pool
Bulle and its castle, in winter
Bulle pool in Gruyère
photograph of a house in the mountains.
Chénens. Chapel and school houses
The Museum of Country and Val de Charmey: Fountain Louis Angéloz
water reservoir lake in the mountains.
construction of the bridge over river.
[Charmey]: Bridge of Javroz
a bus in front of a building.
a man with a horse and cart.
Skiers on the slopes of Moléson with views of the Dent de Broc and the Dent de Follerian
photograph of a herd of cows grazing in a field.
mountain range in the distance.
Cars parked at Place des Ormeaux, Fribourg
Feasted family poses in front of the house
photograph of a family in front of their car.
religious leadership title in a nun's room.
photograph of a family in a field with a tractor and a pick - up truck.
actor as person in the film.
photograph of a woman working in a sewing machine.
soldier with a machine gun in the forest.
photograph of a woman working in a factory.
a nun with her children.
religious leader celebrates western christian holiday.
a statue of film character.
Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey, Fribourg
a family poses for a photo in front of a christmas tree.
film character on a donkey.
religious leader leads a procession through the streets.
Child (little girl) standing in a chair, [Fribourg]
photograph of women in the cloisters.
Young woman sitting on a bench and holding a umbrella, Fribourg
Electric plant, Charmey
photograph of a group of women.
photograph of a group of people.
photograph of a group of women seated around a table.
photograph of a group of people seated around a table.
photograph of a group of men and women.
photograph of a group of men.
photograph of the cricket team.
portrait of a young woman.
photograph of workers in a factory.
Steam boat "Yverdon" arriving at dock on Lake Morat
Skating on Lake Morat (Seegfröni)
women working in a sewing machine.
person, left, and person, right, stand next to automobile model.
a man stands on the shore of a lake with a fishing boat in the background.
Exercise of the body of firefighters at the house Spirgi, rue Principale (Hauptgasse), Morat
a horse - drawn carriage passes through the streets.
a horse - drawn cart in the streets.
portrait of a man with glasses.
a man stands on the shore of a lake.
a group of people standing in front of a restaurant.
students working in a classroom.
elephants walk down a street.
crowds gather to watch the opening ceremony.
photograph of a family sitting in a car.
ballet dancers in the 1960s.
Woman in a boat on Lake Morat
person working on a machine.
photograph of politician addressing a crowd.
House and flooded land, Lake Morat, flood
Two women (Emma Wildanger-Haas and her mother) playing chess
Living room with large window (chairs, table, sofa)
boys playing football on a soccer field.
Woman (Emma Wildanger-Haas) walking her dog by Lake Morat
Französische Kirchgasse (street of the French Church), Morat
photograph of a woman standing in a doorway.
portrait of a woman standing on a dock.
physicist and person at work in the laboratory.
a woman walks through the rubble of her home.
Solemnity, young girls dressed in white wearing garlands, behind school, Morat
Solemnity, young girls dressed in white wearing garlands, behind school, Morat
photograph of a patient in a hospital room.
photograph of a bride and groom standing in a field.
hikers walking on a snow covered mountain.
Delivery of flour bags by Bossy mill in Serrières, rue de l'Hôtel de Ville, Morat
a flooded road.
Lake of Morat frozen, says "Seegfrörni"
Terrace of the restaurant of the Crown Hotel, Morat
a group of people standing in a field.
Baths and beach of Morat
soldiers of the march through the streets.
fishing boat on the beach.
children playing in a field.
Couple (male and female) in grass, Morat
soldiers digging a trench in the streets.
troops marching through the streets.
troops marching through the streets.
automobile model, the first car made by automotive industry business.
noble person arrives in a car.
a family gathers around a christmas tree to celebrate western christian holiday.
Historical shooting of Morat in the presence of General Henri Guisan, Bois Domingue hill (June 21, 1942)
Spectators in traditional costume, Morat Historical Shooting (June 21, 1942), Bois Domingue Hill
photograph of a man holding a giant inflatable balloon.
bride and groom walking down the aisle.
Gathering of youth [sights], [Mort]
a group of children at a christmas party.
children playing on the shore of a lake.
a soldier stands in front of a crowd of people in front of a house.
a tree on a lake.
Commercially exposed refrigerators and washing machines [E. Joggi], Morat
football player with his team - mates before the match against football team.
Jakob Götschi, owner of the Brewery Helvetia, Morat
photograph of the entrance to the building.
Couple on boat trip to Rotary de Morat (29 June 1949), Yverdon-Yvonand
photograph of a group of men and women sitting on the deck of a ship.
a car parked in front of a building.
Terrace of the restaurant of the hotel Murtenhof, Morat
a display case in a shop window.
passengers on a train in the 1950s.
photograph of a group of women sitting in a living room.
reflections in a lake by visual artist.
Cortège de la Solemnité (21 June 1958), girls in white, rue Principale, Morat
wedding of person and noble person.
children reading books in a park.
children playing in the snow.
photograph of a group of young men standing in front of a piano.
Colonial Troops [French soldiers interned in Switzerland], [Morat]
Morat from the scaffolding of the German church
a group of boys pose for a photograph.
vintage photo of a man with his motorcycle.
Motocyclist and his moped Lampretta, rue Principale, Morat
Fisherman on his rowing boat, Lake Morat
Armaillis and wrestler at the wrestling festival, Morat (6 September 1941)
crowds at the opening ceremony.
actor in a scene from the film, directed by film director.
Coral player from the Alps during the historic Murat Shooting
Man on horseback, obstacle jump
Ancient mills of the city at the foot of the castle, Morat
Morat from the shore of the lake
Mount Vully and frozen lake seen from the snow-covered houses of Morat
children playing in a fountain.
School, children on the fountain of Bubenberg, Morat
Main Street and Bern Gate, Morat
House Rübenloch, Main Street, Morat
photograph of a group of young people standing in front of a stone wall.
photograph of a family sitting in a living room.
photograph of a street in the village.
Café "Zur Traube", rue Principale, Morat
Hans and Elisabeth Wildanger playing flute at home, Main Street, Morat
a christmas tree in the home of person.
Restaurant and baths at the foot of the castle, Morat
photograph of a group of seagulls.
photograph of a lake in the 1950s.
Former ditch bordering the ramparts, with the photography workshop (behind the Café du Nord), Morat
painting artist, portrait of a man.
photograph of a sailing boat.
photograph of a rocket being launched from a building.
photograph of a family sitting on a bench.
photograph of a gazebo by person.
photograph of a farmer and his cattle.
Replacing the statue of the Bubenberg fountain with a free copy of Willy Burla, Morat
Bern Gate under renovation, Morat
a photograph of a large tropical cyclone.
photograph of inventor at work in his laboratory.
photograph of a group of men taking a photograph.
Hydravion (Marcel Nappez) on Lake Morat, Vallamand
photograph of a man standing in front of a window.
photograph of the monument to person.
a black and white portrait of religious leader.
statue of builder on the cross.
a house.
late gothic revival structure in the early 1900s.
photograph of a traditional house.
actor in a scene from the movie.
photograph of a group of men walking in front of a building.
photograph of a woman and a man standing in front of a door.
a family gathering for western christian holiday.
photograph of a woman talking on the telephone.
women picking tea leaves in a plantation.
portrait of actor wearing a suit and tie, 1950s.
monarch and noble person looking out of a window.
children playing in the street.
women walking down a street.
Wedding of Emile Gardaz, columnist and writer, children picking candy
passengers board a train for filming location.
Woman laughing, [Fribourg]
a couple in a convertible car.
Couple at the exit of Saint-Nicolas Cathedral during a wedding, Fribourg
photograph of a couple walking down a street.
crowds of people in the streets.
monarch and noble person greet the crowds gathered for the wedding of noble person and noble person.
wedding of noble person and businessperson.
crowds gather outside the house of politician.
boys playing football in the streets.
a group of young people in a church.
Wedding, bride in a living room (with a TV), [Fribourg]
Children's Mass Servants and Bell Ringers, Fribourg
portrait of a young woman lying on a hospital bed.
a bride and groom on their wedding day.
woman walking on the street in winter.
wedding ceremony in the streets.
a group of people sitting in a car.
a group of men and women walking on a bridge in the 1950s.
noble person attends an event.
Married with assorted bridesmaids, Fribourg
politician and his wife at the wedding of person and noble person.
Men and women alcoholics at the Ball d'étudiants des Belles-Lettres, Fribourg
Marinette Brunschwig at an evening of the WIZO (Women's International Zionist Organisation), Fribourg
photograph of a family sitting at a dining table.
Two women at a costume party, [Paris]
a group of men stand in front of a flag.
Couple at a table at the international student ball, Café de la Glâne, Fribourg
Women around the buffet of the functionaries' ball, Fribourg
Michel Abriel celebrating the Eucharist at his first Mass, Villars-sur-Glâne
photograph of politician and his wife at an event.
crowds of people walking down the escalator in a scene from the film.
the wedding of religious leader and noble person.
actor in a suit and bow tie.
crowds gather to see psychedelic rock artist.
Married with assorted bridesmaids, Villars-sur-Glâne
Children (boys) in front of the Augustins during the first communion, Fribourg
politician addresses a large crowd.
dancing in the streets during the parade.
children playing in the street.
Armailli at rest (supported by a car) at the Poya d'Estavannens
a group of men and women working in a field.
children sing during a performance.
dancers perform in front of the hotel.
a group of young people look at a car.
monarch and noble person at the grave of person.
crowds of people on a motor scooter.
a priest speaking into a microphone.
actor and his wife attend an event.
politician and his wife are greeted by a crowd of people as they arrive.
a group of puppets dressed up for western christian holiday.
crowds gather for the wedding of person and noble person.
crowds at a rally for politician.
a nun shares a laugh with a nun.
a statue of religious leader.
a family in the 1950s.
Saint-Sacrement facing the Cathedral at the procession of the Fête-Dieu, Fribourg
monarch and noble person in a scene from the film, directed by film director.
a boy and his father with an elephant.
Children in armpits behind milk bottles, Gruyère
Pierre-Henri Simon and Gonzague de Reynold, professors at the university, during a meeting of the EJN, Cressier-sur-Morat
crowds of people on the beach.
African Student Congress at the University of Fribourg
politician shakes hands with a young girl at an event.
physicist at work in the laboratory.
soldiers receive a certificate of completion from politician.
crowds of people in the streets.
photograph of a crowd of people waving flags.
photograph of a sign for a city.
photograph of a nun in front of a painting.
demonstrators march through the streets.
demonstrators march through the streets.
photograph of politician driving a convertible car.
a group of children playing in the street.
crowds at a football game.
Fête fédérale des jodleurs, parade at Place Georges-Python, Fribourg
Federal wrestling party, combat wrestlers, Fribourg
Scouts gathered for Glaive Routier, activities in the Fribourg countryside
Scouts gathered (Glaive Routier) at the Planche-Supérieure, Fribourg
this is a photograph of the roof of a building.
Music-hall dancers at the Livio Theatre, Fribourg
Arlette Zola, singer, during a show by Radio-Lausanne, Grand-Places, Fribourg
Arlette Zola, singer, during a show by Radio-Lausanne, Grand-Places, Fribourg
ballet dancer on the set of musical comedy film directed by film director.
Nigerian Ballet at the Livio Theatre, Fribourg
young women dancing on the deck of a cruise ship.
photograph of politician addressing a crowd.
a group of young boys playing a game of mini golf.
a man rides a motorcycle through a field.
cyclists nearing the end of stage as it enters a city.
olympic athlete on his way to winning the men's road race.
photograph of a pilot standing next to an airplane.
ice hockey player, left, and ice hockey player, right, play a game of ice hockey.
a group of men clean up the water after a fire broke out.
Women in Sport Dress at CF Friboug's National League B Celebrations, 1952
Children's race (Summer-School), Avenue de Gambach, Fribourg
the team before the match against football team.
a man and a woman standing in front of a van.
photograph of a group of people working in a commercial kitchen.
a young woman and a young man reading a newspaper.
soldiers stand in front of a military vehicle.
a nun wearing a nun's veil.
a group of men and women sit on the steps of a building.
Course at the Institute of Zoology of the University of Fribourg
a group of men sitting at a table in a conference room.
students studying in the library.
members of the women's and men's teams at a dinner party.
Blood donation in the sports hall of the University of Fribourg
Nurse with a woman giving her blood, University of Freiburg
Blood donors eat in the locker room of the Society of fencing, University of Fribourg
visual artist at the exhibition of his work.
politician gives a speech at the graduation ceremony.
Man with a beer on the terrace of the Café des Arcades, Place des Ormeaux, Fribourg
photograph of workers in a factory.
a man working on a tractor.
scientists at work in a laboratory.
Brasserie du Cardinal, Fribourg
photograph of a group of men standing in front of a building.
a man standing in front of barrels of beer.
a group of workers in a factory.
Yard station from the Tower of the Brasserie du Cardinal, Fribourg
a tank on the road.
children playing in the back of a car.
automotive industry business on the road.
Child carrying wood, rue des Augustins, Fribourg
men digging a trench in a street.
construction of the - photo sharing!.
railroad tracks in the 1950s.
actor as film character and actor as film character in a scene from the film.
a vintage advertising poster in the town centre.
Information stand on nylon lingerie at the department store "Aux Trois Tours", Fribourg
Women in swimsuit at the baths of La Motta, Fribourg
a model walks the runway at the fashion show during fashion week.
models walk the runway at the fashion show.
Woman (model) wearing jeans, Fribourg
Female (Miss Switzerland 1953) in swimsuit, Fribourg
Female (Miss Switzerland 1953) in swimsuit, Fribourg
actors and film director
actor in a scene from the film.
a woman stands in front of a window with a man standing behind her.
a mother and her children in the streets.
photograph of a group of people sitting on a bench in a park.
boys on a scooter in the streets.
children playing in the street.
a woman selling ice cream in a street market.
a nun walks down a cobbled street.
a woman carries a bouquet of flowers.
person and actor on the street.
a man walking in the rain.
a group of children play in the snow.
Traffic Officer at Place de la Gare, Fribourg
Court of the University of Fribourg, site Mercy, with students
a family in the kitchen of their home.
a group of children sit at a table in the living room of their home.
a boy and a girl sitting on a snow - covered park bench.
men playing a game of dominoes.
photograph of a woman sitting at a table in a restaurant.
students sitting on a bench.
women working in a factory.
a group of children gather around a picnic table in a village.
crowds gather to watch the parade.
photograph of a group of people walking on a river bank.
a group of people walking along a lake.
Gas plant on the banks of the Sarine River (in flood), Planche-Inferior, Fribourg
horse and cart in the streets.
children playing in a swimming pool.
children play in the fountains.
children playing ice hockey in the snow.
Garage of the Bourg between the churches of Cordeliers and Notre-Dame, rue de Morat, Fribourg
Worker burying telephone cables, Fribourg
photograph of the funeral of military commander.
people waiting for the train.
a group of young people dancing on the street at night.
a baby in a pram.
person at work in the window of her bakery.
children playing in a boat on the beach.
tourist attraction in the rain.
soldiers with their families in front of a house.
children playing in a swimming pool.
children playing in a pool.
a large crowd gathers for a meal.
crowds of people on the street.
actors and film director
photograph of a group of young people sitting in a car.
a man and a woman sit on a bench in front of a building.
children dancing in the streets.
a group of women dressed in traditional clothes, standing in front of a house.
portrait of a boy holding an easter egg.
monarch and noble person with a group of children.
little girls dressed as angels in a church.
people enjoying a picnic on the beach.
horse and carriage in the streets.
a boy on a donkey.
boys playing in the water.
photograph of a group of people sitting on the grass.
a group of boys sit on a bench in front of a fire escape.
portrait of an old man.
Baggage of pilgrims, Rome
Young pilgrims inside St. Peter's Basilica, Rome
Pilgrims on St Peter's Square, Rome
Two women sitting at the coffee table, Fribourg
soldiers sitting on a bench.
Horses at the breeding fair competition, veterinary inspection, Fribourg
a shop window in the neighborhood.
models walk down the runway at the fall fashion show during olympus fashion week.
workers on a construction site.
children play on a playground in the 1950s.
a man and a woman stand next to an elephant at a circus.
a man cooking food.
René Ribotel, ticket seller of La Loterie Romande, Avenue de la Gare, Fribourg
crowds line up to buy a car at a car show.
Sister (religious) of Saint Vincent de Paul, Fribourg
Women in conversation in front of the pipe shooting stand, Fête caraine des Grand-Places, Fribourg
a woman plays the accordion in the street.
photograph of a woman looking out of a window.
a family waits for the arrival of person.
a woman walking down the street.
Woman crossing the street (through the glass), boulevard de Pérolles, Fribourg
man with a bicycle in the streets.
a young girl and her mother cross the street in the 1950s.
soldier helping a wounded man in the streets.
Tour de Suisse (sports cycling), spectators at the Route des Alpes, Fribourg
portrait of a young woman sitting in a hammock.
children playing with a dog in front of a house.
a man sitting at a table with a cup of coffee.
an elderly woman smoking a cigarette.
Sleeping man in front of his glass at the closing of the bistro, Fribourg
children playing baseball in a park.
Children picking up a shoe, Grand-Rue, Fribourg
children playing in the playground.
Balconies of a house in the Auge district, rue des Forgerons, Fribourg
Sisters (religious) of Saint-Joseph de Cluny at the procession of the Fête-Dieu, Fribourg
Children around a "cinema machine" at Freiburg train station
a man sits at a table with a cup of tea and a cigarette in his hand.
Tour de Suisse (sports cycling), cyclists in front of the Ancienne Gare, Fribourg
a family gathers around a table in their living room.
Children in front of a window with an electric train model, [Fribourg]
a a barber at work.
Children singing on May 1, Fribourg
Newsstand and Morris column under the snow, George Python Square, Fribourg
Refurbishment of the roadway of Boulevard de Pérolles, asphalt workers, Fribourg
photograph of a man reading a book in a library.
a farmer with his horse and cart.
women picking potatoes in a field.
Two elderly men sitting on a bench at Place des Ormeaux, Fribourg
a group of soldiers in a parade.
soldiers take a nap in the shade of a tree during military conflict.
a woman walks through a snow - covered park.
children washing dishes in a wheelbarrow.
children playing in a park.
monarch riding a horse during the wedding ceremony of noble person and noble person.
shoes for sale in a shop window.
children playing in the street.
actor with his wife on the beach.
couples dancing on the deck of a ship.
portrait of a boy holding a box.
a butcher waits for customers at a market.
actor walking down the street in a scene from the film.
mother and children in a hospital room.
Cantonnier pushing his wheelbarrow at Rue de la Samaritaine, between 1940 and 1950
children playing in the street.
the toilet in the basement.
students in a classroom.
an old door in an abandoned building.
Sisters (religious) with headphones during the recording of a show by the Chaîne du Bonheur, Fribourg
Institute for young girls "Bon Pasteur", sister (religious) with a journalist, Villars-les-Joncs
politician at work in the kitchen of his family's home.
a church with a cross on the pulpit.
Romont primary school, coat rack
photograph of a family at a dinner table.
François Ody, neurosurgeon, practicing lobotomy at the Cantonal Hospital in Fribourg
a model of the head of military commander is unveiled.
Cigarette collection organized by the Chaine du Bonheur for hospices for the elderly, Fribourg
automobile model in a muddy puddle.
a boy and a girl sitting on the steps of a house.
a group of soldiers sitting on a jeep.
painting artist in front of a painting by painting artist.
children playing in the street.
a man walking his dog on the street.
photograph of men standing in front of a house.
a street performer in the streets.
a man prepares food in the kitchen of his home.
soldiers relax on a park bench.
actors on the set of romantic comedy film directed by film director.
Dancer posing near the river, [Sarine]
Waiting room of the SBB train station, travellers in the early morning, Fribourg
Employee in the telephone booth maintenance service, Fribourg
Socialist posters against poverty and poverty in public premises, 1942-1945
a woman sits on a bench and reads a newspaper.
a man loading a cart with fruit and vegetables into a tractor.
a couple standing on the edge of a cliff looking out to sea.
men working on a river.
Scouts gathered for Glaive Routier, activities in the Fribourg countryside
Rallye de la Madone des Centaures, couple tied on the bike, Fribourg
photograph of a group of men standing in front of a car.
a group of people sit around a table in a restaurant.
a group of men playing a game of football.
a model prepares backstage at the fashion show during olympus fashion week.
Additional service for women (military vehicles), Caserne de la Poya, Fribourg
a young woman sitting on a park bench, reading a newspaper.
a man walks past a dog on a street corner.
Female nude (model of the Academy of Fine Arts), Fribourg
Female nude (model) in Robert Müller's workshop, Paris (France)
a rock climber climbs up a steep rock face.
black and white portrait of a young woman lying on the river bank.
actor in publicity portrait for the film.
Cabaret artist, Fribourg
Gasoline pumps and kiosk on the rue du Simplon, Fribourg
Living room of an apartment with a radio station, between 1950 and 1955
actor in front of a newspaper.
photograph of a horse - drawn carriage.
trucks and cars on the road.
Worker on a pole laying telephone wires
electricity pylons at a power plant.
a group of workers in a factory.
portrait of a young woman wearing a red dress and hat.
street vendor selling fish on the streets.
film director and actor on the set of the movie.
racecar driver at the wheel of his car.
a selection of vintage racing cars.
ice hockey right winger and ice hockey left winger.
Joseph Bovet at the organ of the Cathedral of Saint-Nicolas, Fribourg
Joseph Bovet leads liturgical songs at the Congress of Swiss Catholics, Grand Places, Fribourg
a group of students marching down a street.
Pins in Polish costume for "Four concerts for Polish orphans", Fribourg
children playing on a park bench.
photograph of a group of people in front of a house.
passengers boarding a train at the railway station.
photograph of a group of women standing in a park.
photograph of a young woman sitting on the edge of a mountain.
children playing in the street.
bridge over river in the town.
Grand store "Aux Trois Tours", Rue de Romont, Fribourg
Freiburg station, train on the wharf
Garage de la Gare (Spicher & Cie), former railway station, Fribourg
photograph of the bell tower.
construction of the bridge over river.
an old photograph of the restaurant.
a car is crushed under the weight of a building.
photograph of an apartment building at night.
Livio Theatre, rear façade, Arsenaux Road, Fribourg
Covered market, Comptoir Road, Fribourg
Young women at the Institut des Hautes Études at the Villa des Fougères, Fribourg, in 1950 and 1960.
Brasserie Beauregard and Saint-Pierre church, Fribourg
apartment buildings in the city.
a man on a tricycle crosses a bridge.
transit vehicle type crossing the viaduct.
Pont du Gotteron, construction of the wooden hanger, Fribourg
Pont du Gotteron, construction of the wooden hanger, Fribourg
construction of the new bridge.
construction of the cable - stayed bridge.
construction of the bridge over river.
Gotteron bridge, construction, formwork, Fribourg
tourist attraction in the 1950s.
soldiers with a christmas tree.
tanks pass through a city during a heavy snowfall.
soldiers on the bridge in the snow.
a group of people on a suspension bridge.
Gotteron bridge, construction, dismantling of the apron of the old suspended bridge, Fribourg
men standing on a bridge.
construction workers on the bridge.
crowds at the opening ceremony.
crowds wait for the arrival of politician.
politician waves to the crowd as he arrives.
rock climbing in the late 1800s.
photograph of men on a cable car.
a windmill.
Gotteron bridge, construction, dismantling of the cables of the old suspended bridge, Fribourg
Old bridge suspended from the Gotteron with ropes, Fribourg
Food Fair (15th), Place de Notre-Dame, Fribourg
smoke billows from a burning building.
crowds gather around the ruins.
a group of men gather around a fire in the camp.
a group of motorcyclists waiting for the start of the parade.
photograph of a group of young people in front of a house.
construction of a new housing estate.
crowds gather to watch the parade.
photograph of a group of children holding balloons.
a group of men and women jogging in a park.
a father and son playing kite in a park.
a little girl and a little boy walking down the street.
photograph of monarch and noble person holding hands in front of a crowd of people.
firemen on the scene of a fire.
Out of a water pipe, rue du Pont-Mure, Fribourg
smoke billows from a burning police car.
Repair work for a water main, rue du Pont-Mure, Fribourg
photograph of a shop in the district.
old house in the middle of the street.
a woman sleeping on a bicycle.
a man on a skateboard.
photograph of a bride and groom standing in the doorway of their home.
Pensioners of the home of Providence with a sister, rue de la Neuveville, Fribourg
Pensioners of the home of Providence with a sister, rue de la Neuveville, Fribourg
a group of boys reading a book.
astronaut in the classroom of his private school.
photograph of a man flying a kite.
Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg
crowds of people on the beach.
Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg
Uni sports (university gymnasts), swimming at the baths of La Motta, Fribourg
a group of children sit on the floor of a train carriage.
football team manager shakes hands with the players before the match.
children in a classroom.
cyclists at the start of the race.
automotive industry business in the streets.
crowds gather to watch the parade.
cyclists at the start of the race.
photograph of a group of people standing in front of a building.
the prince of wales receives a bouquet of flowers from a young fan.
photograph of a group of young people waiting for a bus.
boxer throws a punch at professional boxer during a boxing match.
crowds of cyclists and pedestrians cross the road.
Funeral of Jo Siffert (pilot car), rue du Pont-Mure, Fribourg
children playing in the mud.
a man selling newspapers in front of a car.
children playing in the street.
Rue de Romont decorated for Christmas parties, Fribourg
photograph of a man standing in front of a shop window.
photograph of a priest and a nun in front of a church.
actor with his family in a scene from the film.
photograph of monarch and noble person walking down the street.
a mother and her child buying food from a street vendor.
men selling potatoes at the market.
photograph of politician and his wife waving to the crowd.
monarch and noble person in a horse drawn carriage.
a man washing his face in the street.
actors at a restaurant in the 1950s.
a group of men look at a painting by painting artist.
Ferruccio Garopesani, painter, in front of the store of Jean Mülhauser, rue du Pont-Mure, Fribourg
painting artist at work in his studio.
politician inspecting a statue of monarch.
photograph of politician and members of his cabinet at the conference hall.
politician, left, and politician, right, look at a drawing of politician during a meeting.
actors in a car in a scene from the film.
photograph of monarch and noble person talking to each other in front of a church.
photograph of a crowd of people walking down a street.
photograph of a man crossing the street.
crowds gather for the opening ceremony.
american football player sits on the grass with a camera on his shoulder.
american football team running back american football player is tackled by american football player during the first half of a football game.
baseball player throws a pitch during a game against sports team.
photograph of a farmer plowing a field with his tractor.
a group of men playing football in a field.
photograph of a group of women playing a game of kite.
crowds watching a game of cricket.
a group of young men and women playing a game of cricket.
a man jumps on a trampoline at festival.
a man jumps into a swimming pool.
a group of young people at a bar.
olympic athlete and olympic athlete in the swimming pool.
football player, football player, football player, football player, football player, football player and football player.
children jumping into a swimming pool.
a swimmer jumps into the water.
a group of children playing in a swimming pool.
dancers perform during the opening ceremony of festival.
a group of men and women stand in front of a building.
crowds gather to watch the parade.
military parade through the streets.
crowds line the streets for the funeral of military commander.
a group of priests standing in front of a church.
a group of men in white shirts walking down a street.
crowds of people walking in the rain.
crowds gather to watch the parade.
monarch and noble person attend the wedding of noble person and businessperson.
politician addresses the crowd at the dedication ceremony.
a group of young people walking down a street.
wedding ceremony of noble person and businessperson.
dancers performing on a stage.
dancers in a ballet class.
Satus (Fédération Ouvrière Suisse de Gymnastics et de Sport) at the Livio Theatre, Fribourg
Satus (Fédération Ouvrière Suisse de Gymnastics et de Sport) at the Livio Theatre, Fribourg
dancers performing in a scene from the film.
musicians in a scene from the film.
religious leader blesses the altar during his visit.
a group of children gather around a statue of military commander.
a crowd of people gather to watch a procession through the streets.
monarch and noble person at the opening ceremony.
monarch and noble person at the wedding of noble person and businessperson.
crowds gather to hear the announcement of the surrender.
a group of women reading religious text.
crowds gather to watch the parade.
a group of people walking on the street.
soldiers resting in a field.
photograph of a woman walking on the beach.
soldiers marching in the streets.
soldiers resting in a forest.
a group of soldiers jumping over a tree.
photograph of a large group of soldiers standing in front of a large building.
workers dig a trench on a street.
photograph of a man carrying a cardboard box.
tourist attraction in the 1950s.
a worker welding metal on a construction site.
construction of the new bridge.
Schiffenen Dam, construction, workers and wheelbarrow suspended
Schiffenen Dam, construction of the plots from the right bank, general view
photograph of a group of people standing in front of a large bell tower.
photograph of politician addressing a crowd.
Schiffenen Dam, construction, uphill view
fireworks explode from the deck of ship.
construction of a new bridge.
Schiffenen Dam, construction of hydroelectric power station
Schiffenen Dam, construction, lake and dam upstream, fishing children
mountain range in the distance.
men working at a construction site.
Rossens Dam, construction, preliminary works (protection dam)
a group of men working on a construction site.
photograph of a group of men working on a rock formation in the desert.
a group of men climbing up a steep rock face.
a group of miners working in a mine.
a group of workers in front of a fire engine.
Rossens Dam, construction, workers around wagons
a group of men sit on a bridge.
actor in a promotional photo for the film.
a group of people in front of a cross.
men working on a new bridge.
construction of the bridge over river.
construction of a bridge over river.
men working on the roof of a house.
a train on the tracks.
tourist attraction in the 1930s.
tourist attraction in the 1930s.
a plant growing through a hole in a brick wall.
construction workers on the ship.
a bus stopped at a gas station.
a group of construction workers building a house.
construction cranes at a construction site.
photograph of a man lighting a cigarette.
silhouette of a man jumping over a bridge.
photograph of a man standing in front of a water tank.
a young boy with a chainsaw.
black and white photo of a house submerged in water.
monarch and noble person at the opening ceremony.
crowds line the streets to watch the parade.
cars lined up at the start of the race.
construction of the tower, ca.
Rossens Dam, construction, workers laying on a drain line
Rossens Dam, construction, drain line
Rossens Dam, construction, filling of vertical joints
Rossens Dam, construction, rise of water and formation of Lake Gruyère
Rossens Dam, construction, rise of water and formation of Lake Gruyère
water reservoir lake in the 1930s.
construction workers on a construction site.
painting artist at work on the ceiling of his studio.
bridge over river in the 1950s.
suspension bridge in the fog.
a a man walking past a concrete wall.
construction of the - photo sharing!.
construction of a new underground tunnel.
Dam of the Maigrauge, expansion of the Oelberg plant (indoor view), Fribourg
the crew of the first nuclear - powered submarine.
a soldier stands guard at the entrance.
Dam of the Maigrauge, expansion of the Oelberg plant, Fribourg
women working at a construction site.
monarch and noble person arrive for the wedding ceremony of noble person and businessperson.
photograph of a crowd of people walking down a street.
Church of Christ-Roi, construction, boulevard de Pérolles, Fribourg
photograph of politician shaking hands with politician at an event.
a little boy and his father in the streets.
actor and his wife attend an event.
dancing at a wedding reception.
noble person at an event.
actors on the set of romantic comedy film directed by film director.
the wedding of actor and person.
a group of people dancing in the snow.
Cortège de la Saint-Nicolas, Saint-Nicolas on his donkey in the crowd, Fribourg
a group of young people dancing in the street.
religious leader praying in a church.
a group of young people dancing in the street.
Sale of biscômes at the market of the Feast of Saint-Nicolas, Place de Notre-Dame, Fribourg, 1959
photograph of a crowd of people standing in front of a stage.
Cortège de la Saint-Nicolas, torchbearers, Fribourg
people buying sweets at the market.
a group of men lighting a fire in the dark.
actors in a scene from the movie.
a group of children dressed as soldiers stand in front of a building.
Cortège de la Saint-Nicolas, Saint Nicolas and Father Fouettard on the balcony of the cathedral, Fribourg
film character in a scene from the film.
Cortège de la Saint-Nicolas, crowd from the cathedral balcony, Fribourg
photograph of a street vendor in a supermarket.
photograph of a woman looking at clothes in a shop window.
street market in the old town.
photograph of a stall at a market.
flowers for sale at the flower market.
a woman selling balloons at a street market.
transit vehicle type in the 1950s.
Cantonal festival of Fribourgeois music, Morat
actor in a white dress.
photograph of actor at a formal event.
olympic athlete and olympic athlete at the start of the race.
photograph of the football team.
photograph of military commander and person.
crowds at the start of the race.
a group of cyclists stand in front of a building with a sign saying.
photograph of a family sitting on the porch of their home.
photograph of military person wearing a military uniform, standing in front of a marching band.
crowds gather to watch the parade.
photograph of the wedding of politician and person.
actors in a scene from the movie.
Jardin des Grand-Places, inauguration offered by the Rotary Club, Fribourg
tourist attraction in the 1950s.
politician greets the crowd during his visit.
photograph of workers in a shipyard.
olympic athlete competing in a match with olympic athlete.
soldiers pose with an airship during military conflict.
a group of soldiers stand in front of a line of fire.
a group of soldiers pose for a photo.
troops marching through the streets.
a little girl and a little boy holding a christmas tree.
photograph of a house in the 1920s.
monarch and noble person at the ceremony.
a woman withdraws cash from an atm machine.
Teaching of the Café du Tunnel, Fribourg
a narrow street in the old town.
Pedestrian passage towards Rue de Romont, with the temple, Fribourg
a building.
a building.
La Placette supermarket shop, Fribourg
a street scene in the old city.
people crossing the street.
late gothic revival structure from the south.
snow on a tree in winter.
crowds of people crossing the street.
construction of the new building.
soldiers march through the streets.
men working on a rock wall.
Skier jumping, Moléson-sur-Gruyères
mountain range in the background.
one of the old trams.
sailboats lined up at the start of the race.
person in the production of eggs.
electricity pylons in the sky.
men working at a metal factory.
early stage construction of a villa featuring the car port.
a train crosses the viaduct.
group of people walking in a field.
kids playing in the snow.
sunrise over a lake in the countryside.
crowds gather to watch the opening ceremony.
sausages on a conveyor belt.
cooking in the 1950s, photo by person.
the assembly line at the factory.
a tractor ploughing a field.
trucks loading and unloading cargo at the port.
digital art selected for the #.
Elderly woman with a child in front of a farm, Guin
Vignes in the Vully
Farm and tobacco dryers, Broye District
a man on a tractor in the 1950s.
potatoes are loaded onto trucks at the plant.
Micarna factory, butchers with carcasses, Shortepin
a field of sunflowers under a blue sky.
a farmer ploughs a field with his horse - drawn plough.
a man carries a bag of flour on his shoulder.
photograph of politician at a meeting.
photograph of politician at a desk.
photograph of politician shaking hands with a crowd of people.
monarch and noble person in the audience.
photograph of politician shaking hands with politician at an event.
Bakery, Fribourgeois specialities: cupcakes, cuchaule, wonders, anise breads, benichon mustard, croquets, lady's thighs
portrait of a girl in the snow.
Exit from the A12 motorway at Rossens at the nightfall
The Gruyère viaduct on the A12 motorway, Pont-en-Ogoz
teacher and students in a classroom.
a family picnic in the woods.
Armailli in front of a bell window, Gruyère district
portrait of a man with a cowboy hat.
a group of children dressed in kilts.
crowds of people at the market.
people eating at a restaurant.
painting artist at work in his studio.
a man with glasses smiling.
Emile Angeloz, painter, in his workshop, Fribourg
Ferruccio Garopesani, painter, in his workshop, Fribourg
a stained glass window depicting the life of military commander.
a woman working on a sewing machine.
Bruno Baeriswyl, painter, in his workshop, Fribourg
photograph of a group of women preparing food in a kitchen.
Professional Centre, Fribourg
sign on the door of a train station.
photograph of a man getting into a car.
automobile model at the car show.
actor on the set of musical comedy film, directed by film director.
members of the hockey team pose for a team photo.
photograph of a bus stop.
black and white portrait of a senior man.
ice hockey right winger poses for a portrait.
sports team pose for a team photo.
a bouquet of poppies, roses and daisies.
crowds linethe streets to welcome the new year.
flowers and candles are placed at the grave of person.
crowds gather to watch psychedelic rock artist perform on stage.
blues artist performs on stage with a crowd of screaming fans.
a man lying on the grass in a park.
photograph of a group of men standing in a snow - covered street.
actors in a scene from the movie.
demonstrators march through the streets.
a young boy stands on the side of a railroad track with his hands in his pockets as he waits for the train to pass.
crowds line the streets for the funeral of military commander.
photograph of a man reading a newspaper.
a woman holds a bouquet of flowers in front of the building.
crowds of people waiting for the arrival of the pope.
monarch and noble person during a visit.
a child looks through a pair of binoculars.
sculpture by visual artist in the grounds.
photograph of a woman working in a factory.
actor in a dress by film costumer designer.
transit vehicle type in the streets.
people buying fruit and veg at the market.
a shopper walks past a display of chocolates in a supermarket.
people shopping in a supermarket.
photograph of people shopping in a supermarket.
actors
posters for sale in a shop window.
bottles of beer on a shelf in a bar.
digital art selected for the #.
models backstage at the fashion show during olympus fashion week.
photograph of the building at night.
photograph of a woman walking in the street.
Traffic officer at Avenue de la Gare, Fribourg
photographer in a field with binoculars.
sculpture in the church of person.
University of Mercy, Fribourg
people crossing the street.
Bus stop from the train station, Fribourg
Bus stop from the train station, Fribourg
construction of the new building.
photograph of a building in the district.
Staircase of the Court-Chemin, Fribourg
a tree.
the building.
Bulliard building on St-Pierre Street, Fribourg
Migros Shop, Rue St-Pierre, Fribourg
photograph of workers in a factory.
a sign on a railway station.
photograph of a woman sitting on a chair in an empty room.
an old typewriter.
actors on a bicycle in a scene from the film.
pedestrians wait for a bus.
actor on a chair in a scene from the film.
photograph of men drinking beer in a bar.
photograph of politician at a luncheon.
actors
actor and his wife, enjoy a meal at a restaurant.
a group of teenage girls sitting on the steps of a house.
actors in a scene from the movie, directed by film director.
photograph of a woman wearing a hat and holding a glass of champagne.
actors on the set of romantic comedy film directed by film director.
monarch and noble person at a garden party.
politician waves to the crowd.
photograph of a crowd of people walking down a street.
actor dances with actor in a scene from the film.
Marriage
a couple in an open - topped car.
photograph of a group of people standing in a row in a factory.
blues artist performs on stage.
photograph of a group of young people dancing in a club.
actors in a scene from the movie, directed by film director.
a dining room.
dancer on the set of musical comedy film, directed by film director.
Advertising for Majorica beads (woman)
person and actor on the set of tv teen drama.
actor on the couch in a scene from the film.
person at work in the brewery.
newspapers from around the world.
photograph of workers in a factory.
photograph of a man climbing a ladder.
photograph of workers in a factory.
a group photograph of the women's volleyball team.
a man cooking in his kitchen.
a sign.
looking up at the building.
photograph of a man working at a sewing machine.
Man with statue at the Museum of Art and History, Fribourg
Man with statue at the Museum of Art and History, Fribourg
black and white portrait of a young woman.
painting artist as a child.
a close - up of a woman's hand holding a feather.
this is a photo of a lemon and honeycomb in a glass vase, taken by person.
a selection of chocolate chip cookies.
woman washing dishes in the kitchen.
a boy looking out the window of a steam train.
vendors at a market in the old town.
a woman selling vegetables at a market.
a traditional hat on display at festival.
a woman buying cheese from a stall at the market.
a woman walking down a dirt road in a village.
teenage boy and girl sitting on a bench in the mountains.
Mechanical lifts (telepherical) from Moléson, Moléson-sur-Gruyères
snowboarder and person on the slopes.
soldiers stand in front of the control tower.
Fashion show at the Eurotel organised by the boutique Gambetta, Montreux
person and groom walking down the stairs.
photograph of workers in a factory.
actor in a suit and tie, 1950s.
martial artist poses for a portrait.
cattle being judged at a rodeo.
portrait of a girl with her brothers and sisters in the background.
children playing on a beach.
a man standing in front of a bus stop.
photograph of a man and a woman in a chemist shop.
vintage air balloon in the shape of a heart.
actor with a towel on her head.
a family walking through a forest.
the statue of person by visual artist.
the dining room.
the stairs leading up to the second floor.
statue of person in the church.
# of the basketball team poses for a portrait.
portrait of a woman sitting at a desk.
cheeses on a plate with a knife and fork.
students working on a computer.
a church in the city.
Building in Beaumont, Fribourg
the building, designed by architect.
photographer on the road by photographer.
a train at the railway station.
the production line at the factory.
aircraft model being loaded onto a plane.
Advertising for Cardinal beer with a woman
a man walks through a tunnel.
flowers in front of a door.
automobile model in the garage.
a man walking on a treadmill in a subway station.
Léo Hilber at work for the Museum of Art and History (MAHF), Fribourg
Advertising of the Fribourger stand at Placette (Manor) in Fribourg: children eating an American meal (frites, hamburger, soda)
Advertising of the Fribourger stand at Placette (Manor) in Fribourg: children eating an American meal (frites, hamburger, soda)
little girls getting their hair done at a hairdressing salon.
musical group perform on stage in a scene from the film.
monarch and noble person in the church.
visual artist in the workshop of visual artist.
Beaumont district from the construction site of Polytype SA, Fribourg
soldiers march through the streets.
Factory Chocolate Villars, Fribourg
a child plays with a potter's wheel.
Portrait of a young peasant, Broye
politician addresses the crowd at the opening ceremony.
Female employee of the company Milco SA checking the stocks of yogurt, Sorens
the basketball team poses for a team photo.
photograph of the wedding of person and noble person.
sculpture of a man and a woman.
photograph of a group of women seated in a bus.
photograph of a street scene.
person with his horse in the barn.
photograph of a group of women in a forest.
horse - drawn carriages in the streets.
a group of people sitting around a table in a garden.
Jaeger family with tennis rackets (with friends)
musical artist with his orchestra.
photograph of musicians in a recording studio.
photograph of a group of men and women.
children in front of a pharmacy.
crowds at the opening ceremony.
painting artist with his work.
a tram in the streets.
photograph of a group of men walking down a street.
the grave of military commander.
a woman sits on the porch of her home.
photograph of a young woman riding a horse.
a group of men sitting on a bench.
photograph of a woman holding a chicken.
monarch as a young woman.
a group of women working in a village.
photograph of a man and a woman standing in front of a house.
photograph of a snow - covered roof.
horse drawn carriage in the old town.
architectural details of the building.
a statue of military commander.
photograph of an old building.
one of the many churches.
stained glass window depicting the crucifixion of builder.
a replica of a 19th century gothic door.
cricket team pose for a team photo.
photograph of a group of uniformed officers.
photograph of members of the royal family.
photograph of a large group of people in front of a large factory building.
photograph of a cow grazing in the mountains.
photograph of a group of school children.
photograph of a crowd of people waiting to board a train at the train station.
photograph of a group of men and women.
suspension bridge in the 1930s.
Mountain chalet (16th century), Charmey
photograph of a group of men climbing up a mountain.
photograph of a group of people.
photograph of a group of men and women standing in front of a house.
photograph of a group of soldiers standing in front of a row of trees.
transit vehicle type in the 1920s.
photograph of a group of children.
a group of people in front of the church.
photograph of a horse and cart.
photograph of a group of people in front of a building.
photograph of a group of people.
photograph of a crowd of people.
photograph of a family walking in the woods.
photograph of a building in the area.
photograph of a woman working in a kitchen.
photograph of a crowd of people waiting to cross the street.
photograph of a group of soldiers.
photograph of a crowd gathered around a church.
photograph of a group of people marching in a parade.
photograph of a group of children.
photograph of a group of people.
photograph of a group of women dancing.
photograph of the dining room.
photograph of the dining room.
photograph of a group of boys and girls.
photograph of a herd of cows grazing in a field.
photograph of a group of people standing in a field.
poster for the funeral of person.
photograph of a man standing in front of a building.
photograph of a burning building.
photograph of a water pump.
photograph of a man standing in front of a fountain.
a group of men and women with bicycles.
photograph of a family standing in front of their house.
portrait of a young woman.
family portrait of a family.
portrait of a girl with her dog.
arch bridge in the late 19th or early 20th century.
Red Tower, Fribourg
a woman sitting in a car.
Man perched on the Viaduct de Grandfey, Fribourg
photograph of a wagon loaded with hay.
photograph of a group of men.
photograph of members of the team.
photograph of a woman playing a flute.
Subway from Freiburg train station, Beauregard side
a group of soldiers in front of a motorcycle.
children playing in the water.
photograph of a group of women.
photograph of a man working at a sewing machine.
photograph of an airship flying over a building.
photograph of a man standing in front of a shop window.
olympic athlete in action during a training session.
children playing in a canal.
employees working in a factory.
painting artist at work in the studio.
photograph of a family in front of a gas station.
an old typewriter.
construction of the new building.
photograph of a group of people in front of a shop.
crowds gather to watch the parade.
Works prior to the construction of the cantonal and university library at the top of the Varis, Fribourg
monarch and noble person in front of the cathedral.
photograph of a group of musicians holding a guitar.
a group of women and children in a laundry room.
photograph of a group of men and women seated around a table playing a game of football.
photograph of a group of men in suits and ties.
photograph of a group of people in front of a house.
a family portrait of the family.
photograph of the baseball team.
monarch and noble person celebrate the wedding of noble person and businessperson.
photograph of a group of men in uniform.
photograph of a group of musicians.
photograph of a group of men sitting in front of a house.
a group of men and women pose for a group shot.
a group of men standing in front of a brick wall.
photograph of a group of soldiers.
photograph of a crowd of people.
suspension bridge in the 1930s.
photograph of a group of people in front of a building.
a house.
a portrait of a man dressed as a clown.
politician and his wife pose for a portrait.
photograph of a woman working on a sewing machine.
Blessing Mass of Landsturm troops at Viaduc de Grandfey, Fribourg
soldiers riding in a jeep.
cars lined up on a street.
a man stands in the snow.
photograph of a man standing in front of a snow - covered tree.
a a horse - drawn carriage.
Bains du Boulevard ou Bains Galley, Quartier d'Alt, Fribourg
photograph of a medical practice.
nurses working in a hospital.
employees working in a factory.
photograph of a group of men working in a workshop.
monarch and noble person with a group of children.
men loading a fire engine onto a truck.
photograph of a young girl holding a sword.
Freiburg train station, Beauregard side
photograph of a group of musicians.
the wedding of noble person and businessperson.
photograph of a group of people.
photograph of a landscape with mountains in the background.
tourist attraction in the 1930s.
a man standing next to a car.
tourist attraction in the 1930s.
person, a sculptor by profession, stands next to his work.
Abattoirs of the city of Fribourg (Varis), suspended carcasses
a group of men and women standing in front of a fire engine.
photograph of men standing in front of a ruined building.
tourist attraction in the 1930s.
Hairdresser Antoine Huber, Rue de Lausanne 88, Fribourg
a portrait of religious leader.
cantilever bridge in the 1930s.
Livestock market at the Planche-Supérieure, Fribourg
tourist attraction in the 1930s.
Inauguration of the Zaehringen Bridge, Fribourg
crowds gather for the funeral of military commander.
ruins of the old town.
Hotel Terminus (Zaehringenhof), entrance, train station avenue, Fribourg
construction of the new stadium.
a a man walking along a river.
Livestock Fair, Grand-Places, Fribourg
people waiting for the ferry.
tourist attraction in the early 1900s.
drawing of the building by person.
a man stands in front of a building.
Collège Saint-Michel, Fribourg
politician and his wife in a horse drawn carriage.
Beating of the Grandfey viaduct, Fribourg
General meeting of the Swiss Student Society, Place Georges-Python, Fribourg
a train passes through a city.
Funicular workers linking the Neuveville district to St-Pierre, Fribourg
soldiers in front of a building.
Renovation work at the Pont du Milieu, Fribourg
Traffic on Rue des Bouchers, Fribourg
Traffic at the rue du Pont-Mure, Fribourg
Cantonal Psychiatric Hospital (Overview), Marsens
portrait of a young man.
a man with a mustache.
photograph of a group of people sitting in a car.
Sodalitas Labour City Housing Building, Rue des Cliniques, Fribourg
tourist attraction in the 1930s.
Fribourg (Sarine), Rue Saint-Pierre Canisius 10/20, Collège Saint-Michel (1582), former gymnastics hall, outdoor [Katholiken Tag]
portrait of a boy and a girl.
photograph of a group of men and women seated in a wheelbarrow.
photograph of a man working in a laboratory.
ducks swimming in a river.
photograph of a family with their dog in front of a house.
photograph of politician walking down the street.
photograph of a group of soldiers.
Inauguration of a commemorative plaque (regiment 7), Place Notre-Dame, Fribourg
photograph of a man with his horse and cart in a village.
crowds gather to watch the parade.
crowds gather to see the unveiling of the new school building.
photograph of a group of men working on a machine.
photograph of politician walking down the street.
photograph of a group of people working in a field.